Read Paper 《Omnidirectional Scene Text Detection with Sequential-free Box Discretization 》
Contents
URL: https://arxiv.org/abs/1906.02371
TL;DR
IJCAI 2019 short paper 全方向场景文本检测
Dataset
- ICDAR 2017 MLT: 超大多语言场景文本数据集,包含九种语言18k张图,用四边形的四个顶点标注。
- MSRA-TD500: 室内外文本检测小数据集,300+200
- ICDAR 2015 Incidental Scene Text: 有向场景文本检测数据集,图像多是街景,水平文本。
- HRSC2016: 船只检测数据集。
Algorithm
作者引入了Key-Edge的概念,就是文本标记四边形框的四个顶点的八个坐标,x和y分别按大小排列。
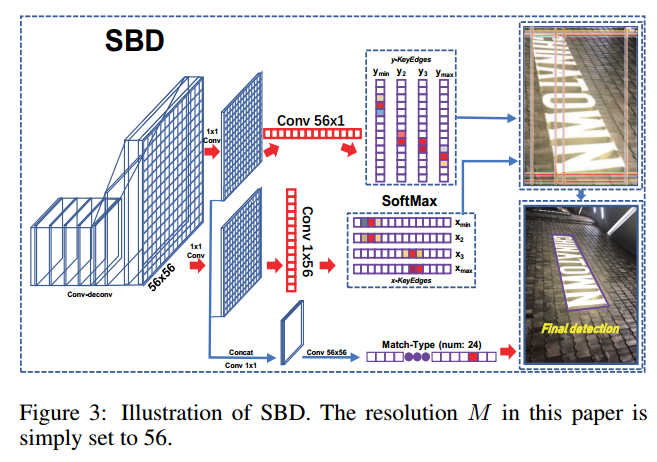 回归边界的时候学习这八个KE,然后在学习匹配模式,从而得到最匹配的四边形边界,并避免标签混淆问题。
文中表示对KE匹配模式的学习很容易收敛。
回归边界的时候学习这八个KE,然后在学习匹配模式,从而得到最匹配的四边形边界,并避免标签混淆问题。
文中表示对KE匹配模式的学习很容易收敛。
Model
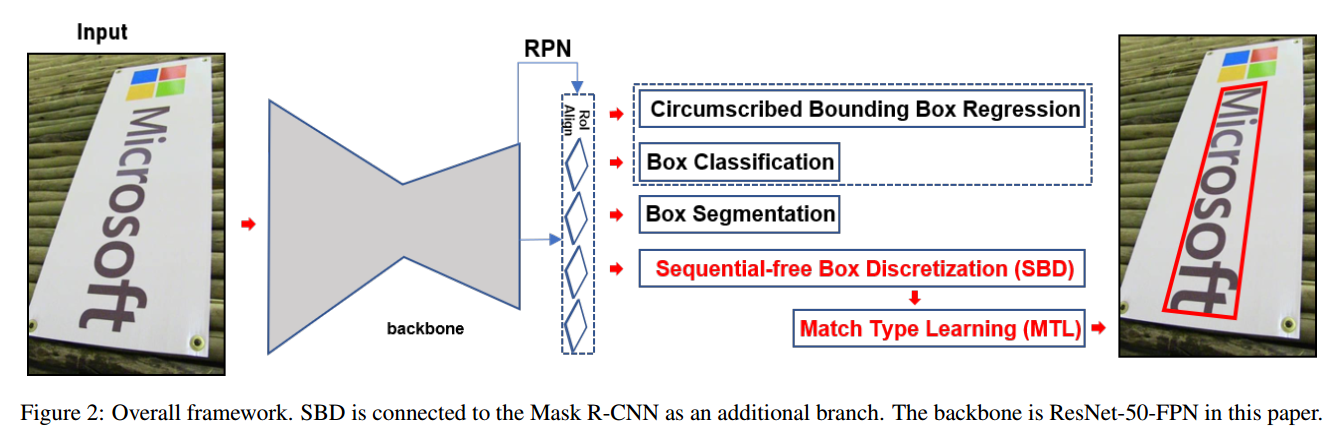 模型基于Mask R-CNN,修改了边界框预测部分。
模型基于Mask R-CNN,修改了边界框预测部分。
Experiment Detail
在三个场景文本数据集上的实验显示本文的方法显著提升了召回率,并提升了综合效果,部分准确率有下降。
 在多方向船只检测上也有明显提升。
在多方向船只检测上也有明显提升。
Thoughts
本文提供了一个很新颖的一般四边形框的生成思路。
Author lvcudar
LastMod 2019-06-08