Read Paper 《Depth Growing for Neural Machine Translation》
Contents
URL: https://arxiv.org/abs/1907.01968 https://github.com/apeterswu/Depth_Growing_NMT
TL;DR
一般序列到序列模型,随着网络的加深性能会下降,且难以训练。 本文提出分层训练更深且效果更好的序列到序列模型的策略和分块构造更深层序列到序列模型的方法。
Dataset
WMT: 大规模机器翻译平行语料
Model
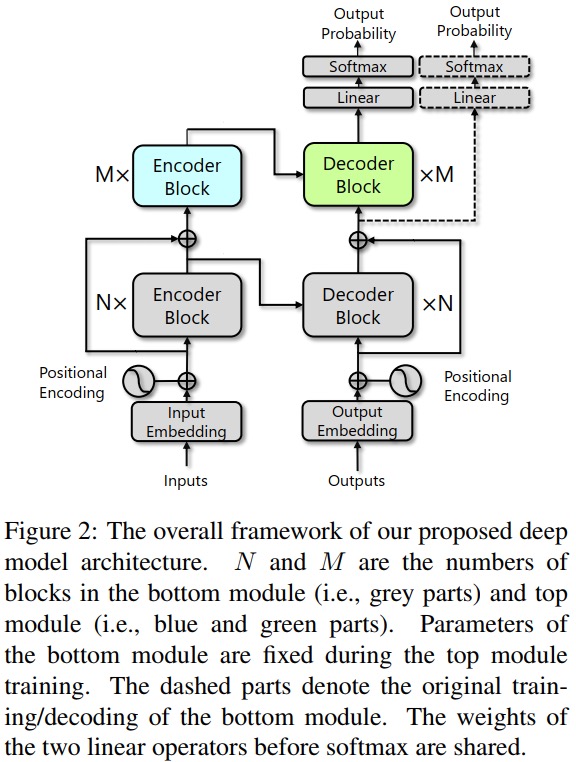
模型分为上下两部分,基于transformer构建。
上下两部分的连接采用了残差方式,以保障梯度传递。
attention也分开计算。
Algorithm
论文介绍分别训练两部分,具体在代码中分为4步训练 1. 训练底部模型并收敛固定 2. 稍微训练一下更深的模型,比如只训10轮 3. 用这时的底部参数初始化顶部模型 4. 彻底训练顶部模型
Experiment Detail
相比于一般不超过6层、越深越差的序列到序列模型,本文在此基础上训练的8层模型取得了明显提升。
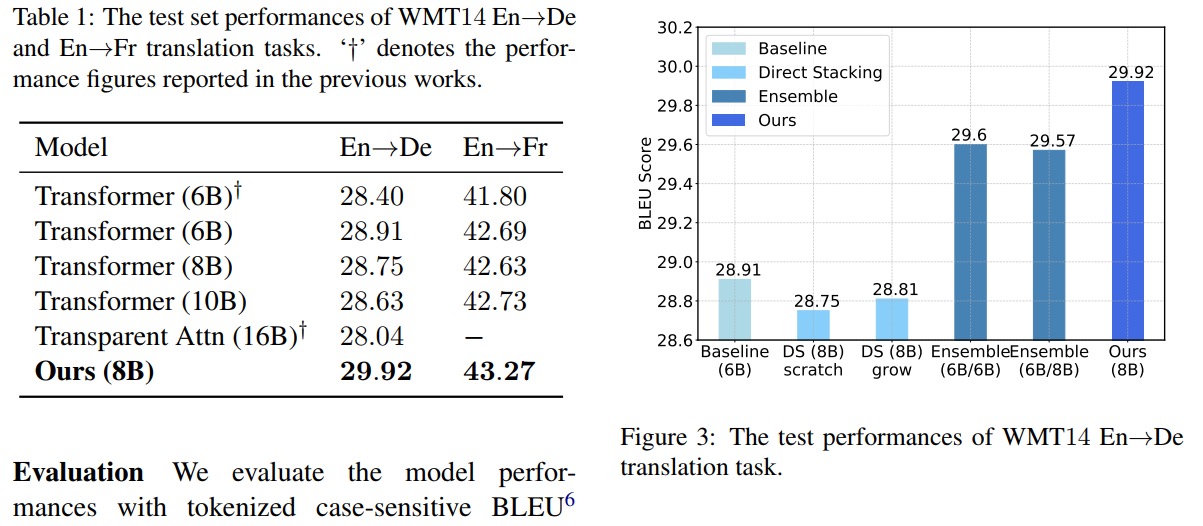 通过消融实验,证明了简单堆叠到8层而不使用残差,和将上下两部分组成集成模型都远远不如本文的方法。
通过消融实验,证明了简单堆叠到8层而不使用残差,和将上下两部分组成集成模型都远远不如本文的方法。
Thoughts
这个序列到序列训练更深的模型提供了思路。
Author lvcudar
LastMod 2019-07-04