Read Paper 《GA-DAN: Geometry-Aware Domain Adaptation Network for Scene Text Detection and Recognition》
Contents
URL: http://arxiv.org/abs/1907.09466
TL;DR
整合外观变换和几何变换,实现多模态学习,更好的适应不同视角的目标检测,并在场景文字检测中验证。
Dataset
ICDAR2013/2015: 鲁棒阅读竞赛数据集,包含各种条件下的文档图片。 MSRA-TD500: 室内外包含文字的照片。 IIIT5K: 5000有限词典的包含场景文本和数字的图片。 SVT: 来自谷歌街景的图片。 CUTE: 挑选的少量扭曲的文字的图片。
Algorithm/Model
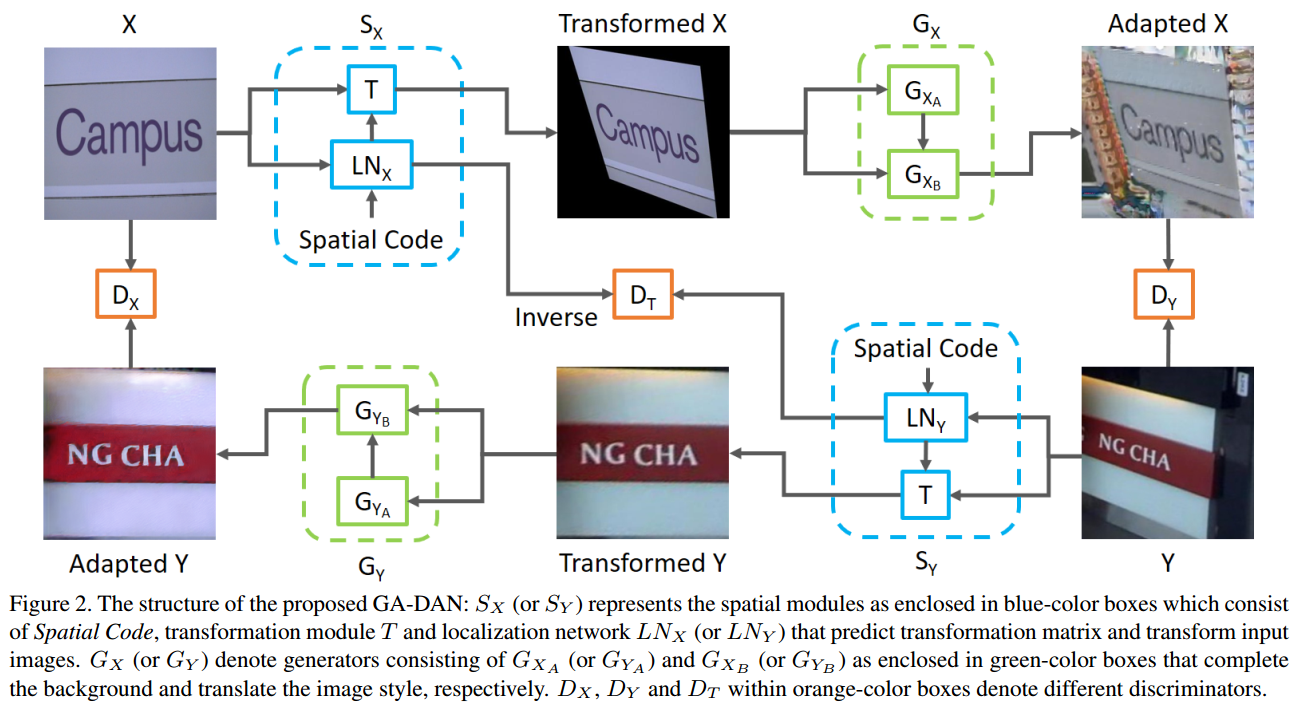 对于一张图片用空间变换网络根据指定的空间编码(视角)进行变换,然后再通过生成网络补全周围环境。
变换网络有变换和定位两个子网络组成,生成也由背景完成和表面适应两个子网络构成,这都是为了能让效果更逼真稳定。
为了约束变换的一致性,对两个定位网络通过鉴别器保持循环一致,同样几何形态(空间形态)的数据也通过鉴别器保持一致。
最终实现为给出的图片提供多种视角下的新图片。
对于一张图片用空间变换网络根据指定的空间编码(视角)进行变换,然后再通过生成网络补全周围环境。
变换网络有变换和定位两个子网络组成,生成也由背景完成和表面适应两个子网络构成,这都是为了能让效果更逼真稳定。
为了约束变换的一致性,对两个定位网络通过鉴别器保持循环一致,同样几何形态(空间形态)的数据也通过鉴别器保持一致。
最终实现为给出的图片提供多种视角下的新图片。
Experiment Detail
实验好像是用不同的网络做数据增强,然后看那种网络增强的数据能训练出更好的完成场景文字的检测和识别。 数据集划分上采用ICDAR2013和ICDAR2015+MSRA-TD500作为不同视角数据训练变换,然后增强数据,在SVT和CUTE上进行测试。
Thoughts
这个子网络堆叠的好复杂,应该需要更清晰一些。 不了解领域适应方面的研究,对实验方法很疑惑。
Author lvcudar
LastMod 2019-07-24