Read Paper 《Learning to Select, Track, and Generate for Data-to-Text》
Contents
URL: https://github.com/aistairc/sports-reporter
TL;DR
像人一样追踪结构化数据的亮点,并写出摘要。
Dataset
ROTOWIRE-MODIFIED (未上线)
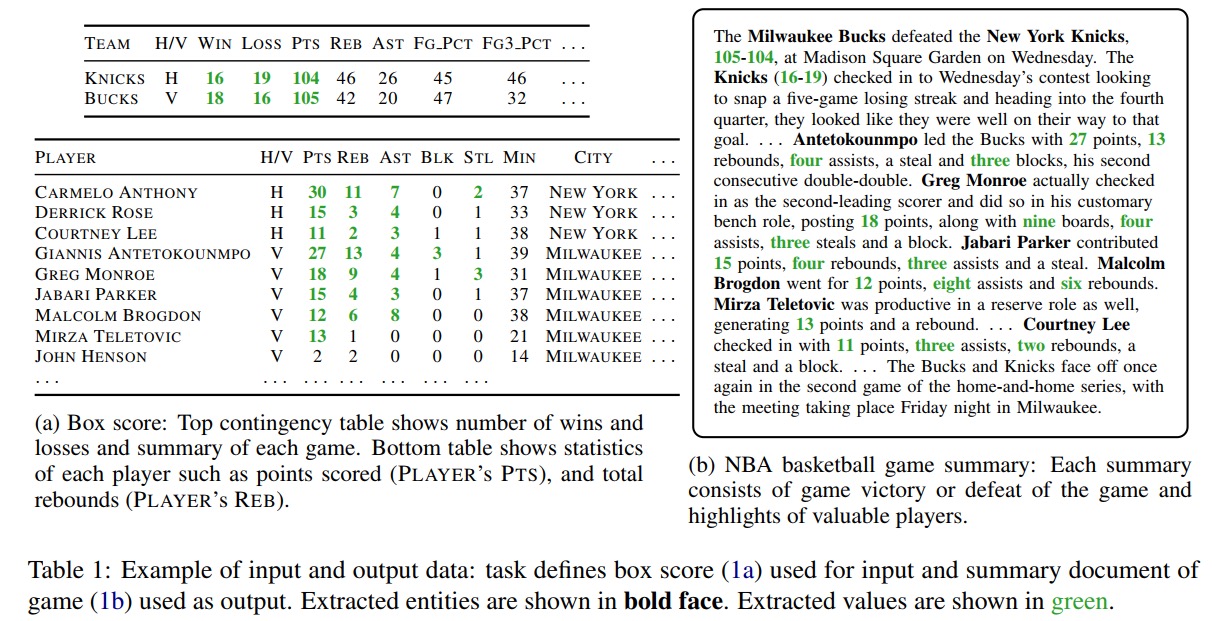
类似EMNLP2017的ROTOWIRE数据集,记录了NBA篮球赛得分判罚数据和对应的报道文档,并进行了筛选和标记写稿人。
Algorithm
作者同以往研究将Data制作成编码序列通过RNN模型得到摘要。 本文的工作主要在设计隐含状态及其更新。 作者将隐含状态分成语言模型Hlm和所关注的数据项Hent两部分。 所关注的数据项用来表示当前关注哪条数据,通过已有生成和上一个隐含状态来更新当前缩关注的条目,如果是之前被关注过的条目则复制之前的Hent,否则通过门限网络计算新的Hent。 输出过程采用复制机制着重复制数字信息,毕竟是篮球比赛的数据集。
Experiment Detail
除了广泛使用的BLEU,这里还有一些专用的指标: * RG: relation generation -所有抽取的关系中正确的比例 * CS: content selection -生成结果中包含的关联条目/参考信息中包含的关联条目 * CO: content ordering -关联条目的顺序
作者和两篇相似的研究进行了对比:
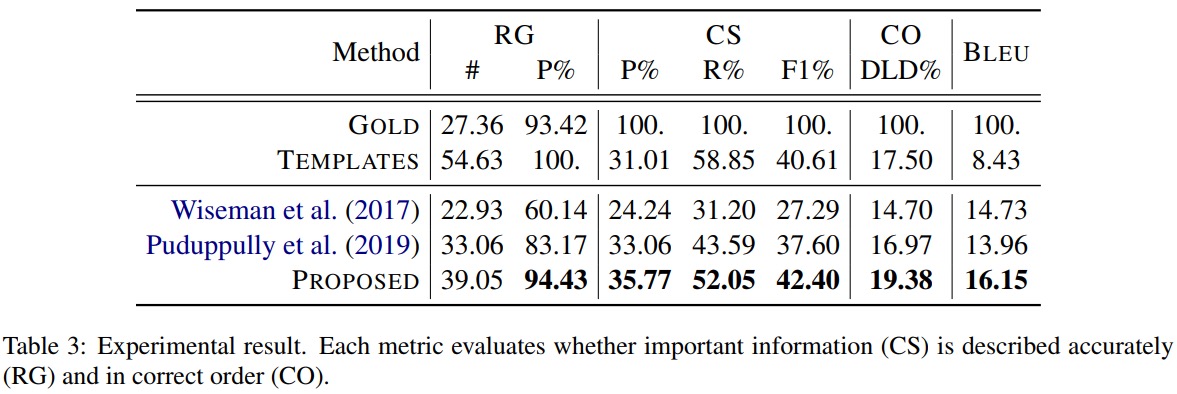 最后作者还实验说明了添加报道写稿人信息能提升所有三个模型的效果。
最后作者还实验说明了添加报道写稿人信息能提升所有三个模型的效果。
Thoughts
添加写稿人信息可以理解为让输出更符合数据集的形式以提高分数。 文中附的链接都404。
Author lvcudar
LastMod 2019-07-27