Read Paper 《HireNet: a Hierarchical Attention Model for the Automatic Analysis of Asynchronous Video Job Interviews》
Contents
URL: http://arxiv.org/abs/1907.11062
TL;DR
AAAI 2019 在大型异步面试数据集上构建注意力机制,分析明显的行为特征预测候选人是否值得雇佣,并提供可视化以供用户评估效果。
Dataset
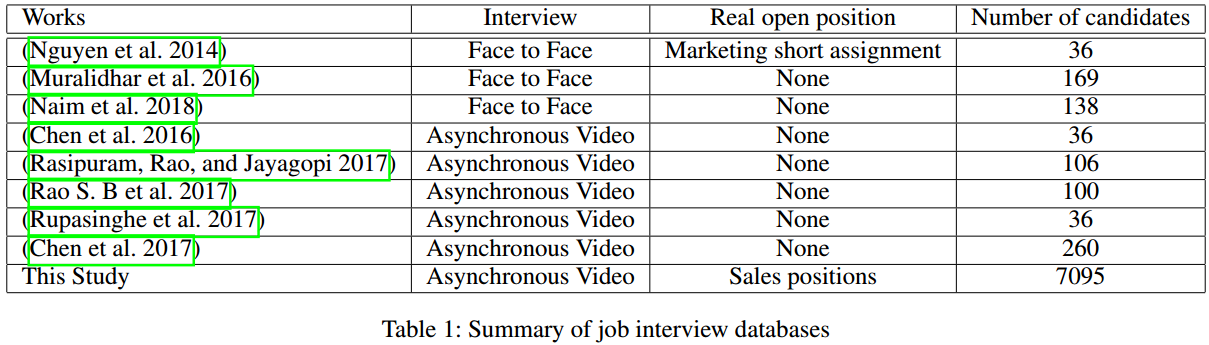 作者调研发现之前只有一个真正真实的面试数据集,于是从ROME Database(法国政府的一个数据库)收集了销售岗位的数据,进行了专业的标注,构建了最大最真实的异步面试数据集。
标注似乎只是是否值得雇佣的二分类标注,不同HR的标注不同采取投票方式。
但是考虑隐私政策,这个数据集不会被完全公开。
作者调研发现之前只有一个真正真实的面试数据集,于是从ROME Database(法国政府的一个数据库)收集了销售岗位的数据,进行了专业的标注,构建了最大最真实的异步面试数据集。
标注似乎只是是否值得雇佣的二分类标注,不同HR的标注不同采取投票方式。
但是考虑隐私政策,这个数据集不会被完全公开。
Algorithm&Model
作者先对面试的筛选过程做了四个假设,大意就是异步面试能包含所需信息并且适合注意力机制来提取。
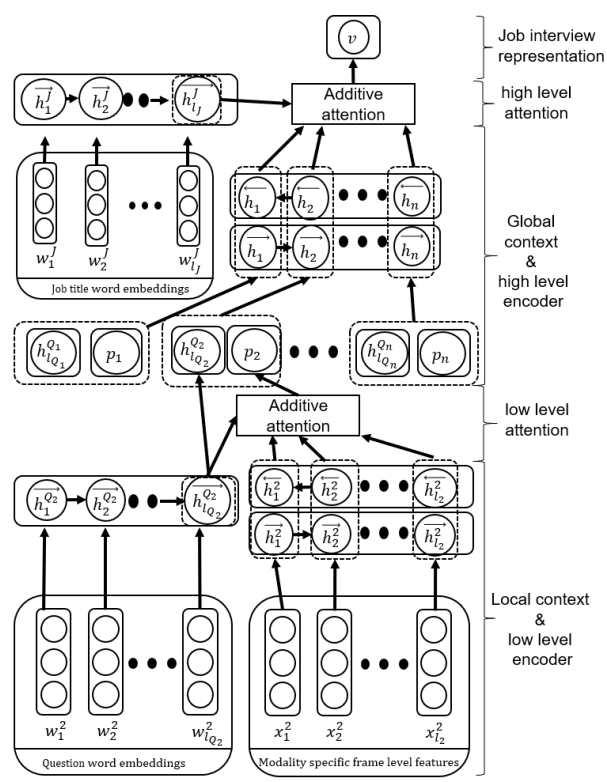 模型结构如图所示,基于双向GRU的循环神经网络和注意力机制。
首先用Word2Vec、eGeMAPS、OpenFace提取提问文本、回答语音、面试图像的特征构成序列。
一方面通过双向GRU循环网络得到音视频的低级表示,另一方面通过单向GRU得到问题文本的低级表示。
然后通过一层注意力机制将问题和回答的特征进行匹配。
接着,一方面再通过双向GRU循环网络得到问答的高层表示,另一方面将职位描述的文本通过单向GRU循环网络得到职位特征的表示。
最后再用注意力机制整合问答过程特征和职位特征,作出是否适合雇佣的分类。
模型结构如图所示,基于双向GRU的循环神经网络和注意力机制。
首先用Word2Vec、eGeMAPS、OpenFace提取提问文本、回答语音、面试图像的特征构成序列。
一方面通过双向GRU循环网络得到音视频的低级表示,另一方面通过单向GRU得到问题文本的低级表示。
然后通过一层注意力机制将问题和回答的特征进行匹配。
接着,一方面再通过双向GRU循环网络得到问答的高层表示,另一方面将职位描述的文本通过单向GRU循环网络得到职位特征的表示。
最后再用注意力机制整合问答过程特征和职位特征,作出是否适合雇佣的分类。
Experiment Detail
作者的实验主要是消融实验和可视化。
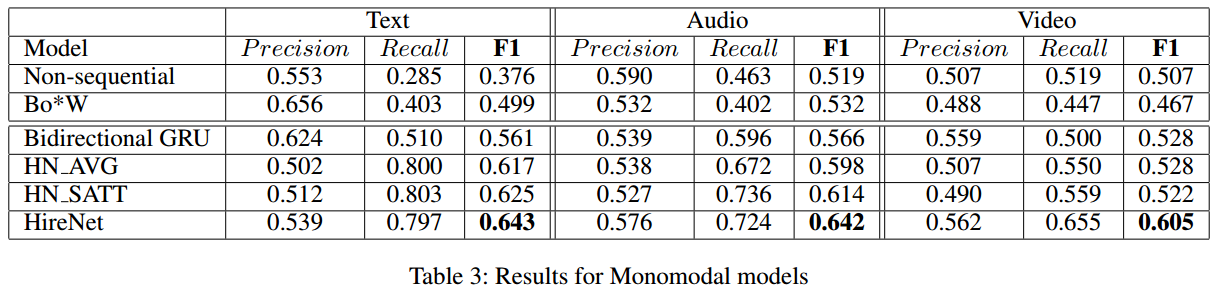 通过消融实验作者对之前的假设进行了验证,并说明互注意力、序列化特征的重要性。
当然作者也和随机方法作了比较。
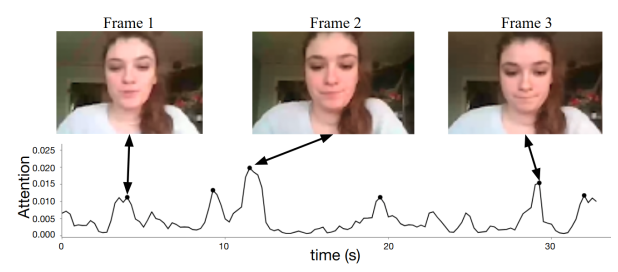
最后作者可视化了注意力参数,展示了重要时刻能够被指示出来。
通过消融实验作者对之前的假设进行了验证,并说明互注意力、序列化特征的重要性。
当然作者也和随机方法作了比较。
最后作者可视化了注意力参数,展示了重要时刻能够被指示出来。
Thoughts
这似乎就是在异步面试数据集上实践了一下注意力机制及其可视化,二分类指标也不是很高。 不过能构造出这么复杂而有效的网络也着实不易。 这里循环神经网络的结构、注意力的形式等超参数也许可以用架构搜索得到,或者作者也是搜出来的。
Author lvcudar
LastMod 2019-08-06