Read Paper 《PARABANK: Monolingual Bitext Generation and Sentential Paraphrasing via Lexically-Constrained Neural Machine Translation》
Contents
URL: http://decomp.io/projects/parabank/
TL;DR
一个英文句子复述改写的数据集基线,通过机器翻译和词法约束构造。
Dataset
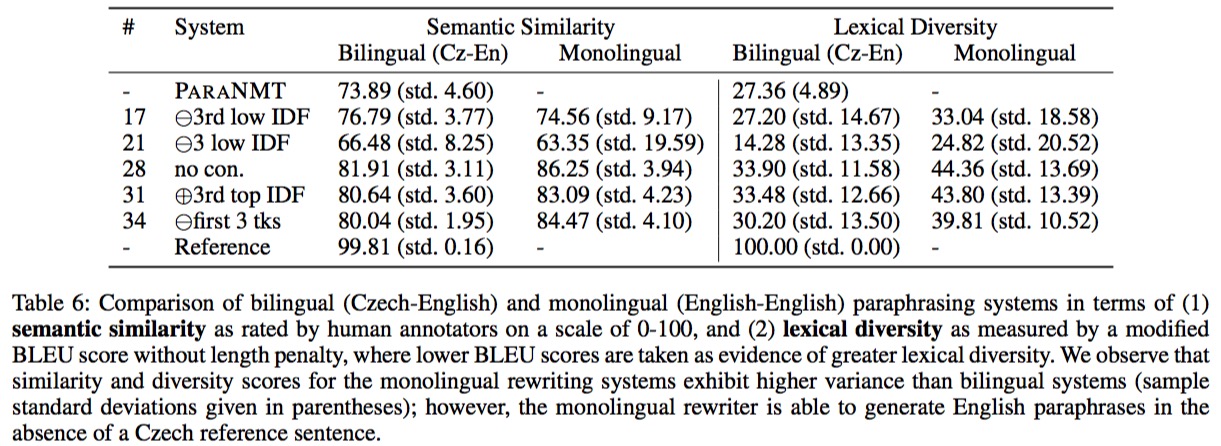
本文的ParaBank包含79.5M参考句和人工打分。 研究方法主要基于ACL2018的ParaNMT-50M,那是一个50M的复述改写数据集; 并参考经典的PPDB(Paraphrase Database) 本文的数据集参考句有更好的语义相关,和更多样的词法结构。
Algorithm/Model
- 通过捷克语-英语数据训练复述改写的机器翻译模型,即把同一句或相似句的捷克语对应的英语参考作为复述改写的参考。
- 通过词法约束选择输出,主要是要求必须出现或必须不出现什么词。
- 通过反向文档词频筛选掉异常频繁或不频繁的词(保留介词),这里作者随手拍了个阈值,优化留着以后做。
- 形态约束:去掉仅仅改变时态语态的参考句。
- 位置约束:要求复述的输出不能仅仅改动前几个词(参考文献的经验)。
- 将和PPDB数据集相似的情况,去那个数据集查询以做约束。
Experiment Detail
实验主要和ParaNMT对比语义相似性和词法多样性,同时通过消融实验证明本文的各种trick的作用。
Thoughts
感觉满满的trick。
Author lvcudar
LastMod 2019-08-10