Read Paper 《Mask and Infill: Applying Masked Language Model to Sentiment Transfer》
Contents
URL: https://www.ijcai.org/proceedings/2019/732
TL;DR
对于非平行数据的情感转换,采用遮挡原始句子中情感的部分并替换来实现。
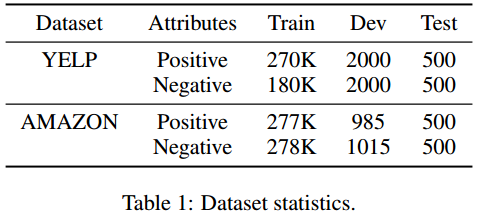
Dataset
YELP和AMAZON的商品评价数据集,评价被标记为正面和负面。
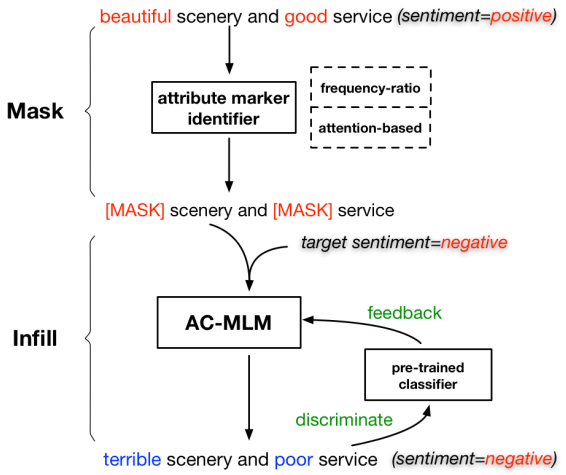
Algorithm
情感反转通过遮挡和填充两部分。
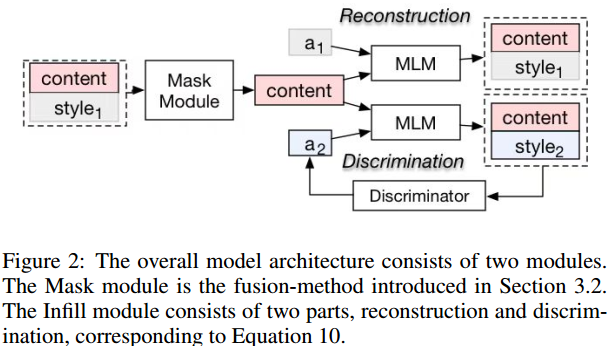
首先用词频相关性和注意力机制结果相乘,预测出句子词序列中表示情感的位置,并尽可能大的生成遮挡。
\( s(u, a) = \frac{count(u, D_a) + \lambda}{(\sum_{a' \in A, a' \ne a}count(u, D_{a'})) + \lambda} * p, \text{ p is attention} \)
然后将有遮挡的句子和反向标签交给AC-MLM遮挡语言模型进行句子补全。
Model
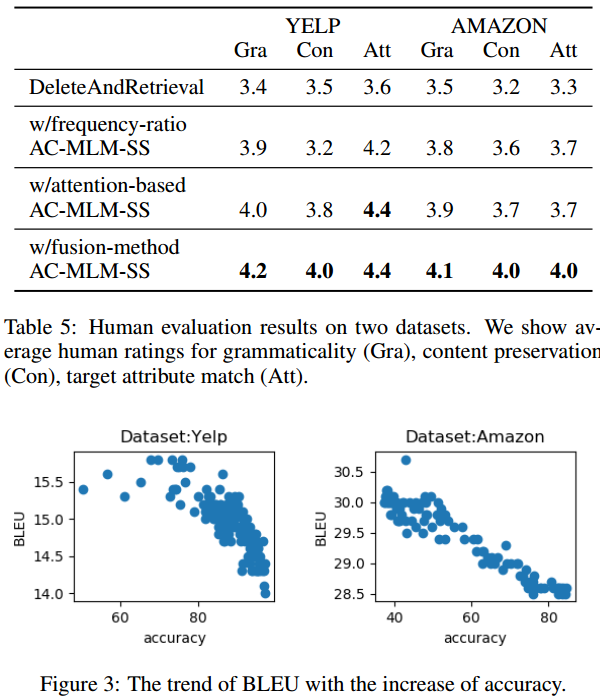
Experiment Detail
作者和近几年的风格转换模型进行了比较,在精度和完整性上都取得了最优的结果。
消融实验证明了混合识别情感mask的效果。
Thoughts
很好的利用了预训练模型,但是混合识别显得比较简陋。
Author lvcudar
LastMod 2019-08-23