Read Paper 《HIERARCHICAL GENERATIVE MODELING FOR CONTROLLABLE SPEECH SYNTHESIS》
Contents
URL: https://google.github.io/tacotron/publications/gmvae_controllable_tts
TL;DR
ICLR 2019 一个可控的语音合成模型,能使用较少的标注从复杂的环境中得到说话者的风格进而按照文本合成语音。
Model
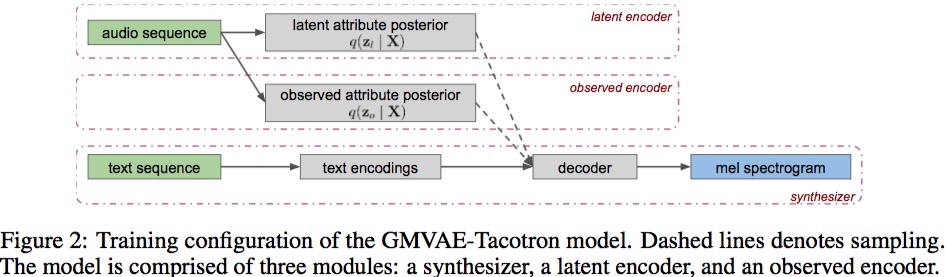
模型是将文本$Y_t$和可选的标签$y_o$输入,通过变分自编码器结构得到音频X。
作者假设了潜在的离散特征$y_l$和连续特征$z_l$,并构建联合概率分布
$p(X, y_l, z_l | Y_t, y_o) = p(X | Y_t, y_o, z_l)p(z_l | y_l)p(y_l)$
其中$z_l$的边缘分布假设为高斯混合模型,期待能捕捉隐含特征,而$y_l$假设无先验。
Experiment Detail
虽然数据集几乎不公开,不过作者在项目主页展示了很多合成效果。
Author lvcudar
LastMod 2019-08-29