Read Paper 《Generating Sentences from Disentangled Syntactic and Semantic Spaces》
Contents
URL: https://github.com/baoy-nlp/DSS-VAE
TL;DR
ACL 2019 使用变分自编码器生成句子,通过损失函数使得语法和语义空间分离,从而在无条件生成、复述、风格迁移方面取得更优的结果。
Algorithm
将变分自编码器的潜空间分割为独立的语法和语义两部分。 \( p(x) = \int p(z)p(x|z)dz \Rightarrow p(x) = \int p(z_{sem}) p(z_{syn}) p(x|z_{sem}, z_{syn}) dz_{sem}dz_{syn} \) 类似的通过最大化改进的时间最小边界(ELBO)进行训练。 \( \log p(x) \ge \mathrm{ELBO} = \mathop\mathbb{E}\limits_{q(z_{sem}|x)q(z_{syn}|x)} [\log p(x|z_{sem}, z_{syn})] - KL(q(z_{sem}|x) || p(z_{sem})) - KL(q(z_{syn}|x || p(z_{syn})) \)
考虑到语法有无穷形式,所以采用线性化到语法树到编码来控制生成到语法。
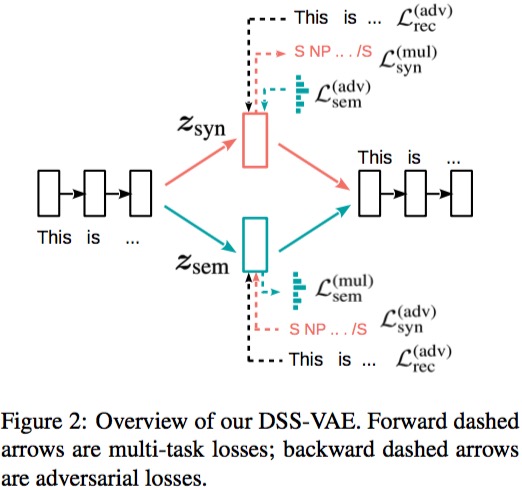
Dataset
- Penn Treebank: 用于重构和无条件生成
- Quora dataset: 用于无监督复述,https://www.kaggle.com/c/quora-question-pairs/data
- Stanford Natural Language Inference: 用于语法迁移, 这里选取了其子集
Experiment Detail
作者在重构和无条件生成、无监督复述、风格迁移三个方面进行了实验,并取得了最好的结果。
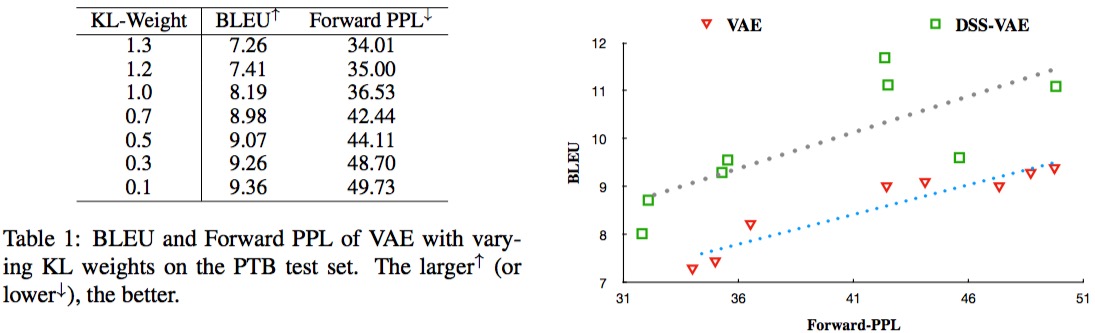
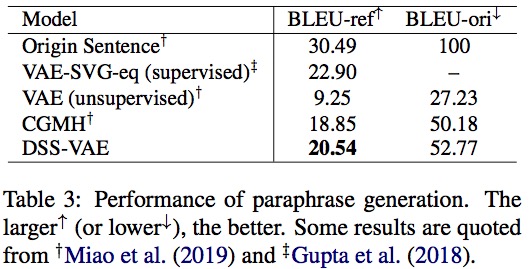
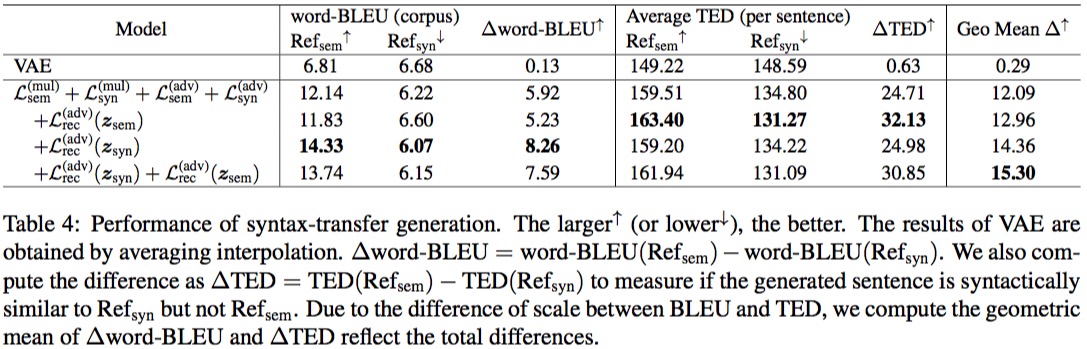
Thoughts
需要重构对抗损失说明两个空间的假设分布是不独立的。
Author lvcudar
LastMod 2019-08-31