Read Paper 《ScisummNet: A Large Annotated Corpus and Content-Impact Models for Scientific Paper Summarization with Citation Networks》
Contents
URL: https://aaai.org/ojs/index.php/AAAI/article/view/4727
TL;DR
AAAI 2019 加入对社区贡献情况的科学论文自动摘要。构建了新的数据集,不以原文摘要为参考,而是结合社区影响(引用网络)人工标注的新摘要。
Dataset
1000篇被引用的计算语言学论文,根据引用情况改写的新摘要及高亮标记。 https://cs.stanford.edu/~myasu/projects/scisumm_net/index.html
Algorithm
对于一篇论文,每篇参考它的文献被标注了参考句。这里通过tf-idf余弦相似性找出这片论文中被引用的部分,选取最相似的两个作为数据。 将原始摘要和这些引用句整合起来作为输入,同时用tf-idf余弦相似性构建所有这些被抽出的句子之间的关系。 为了拟合不同作者(引用者)之间的差异,为每位作者通过他的所有文章建立特征随着句子输入模型。
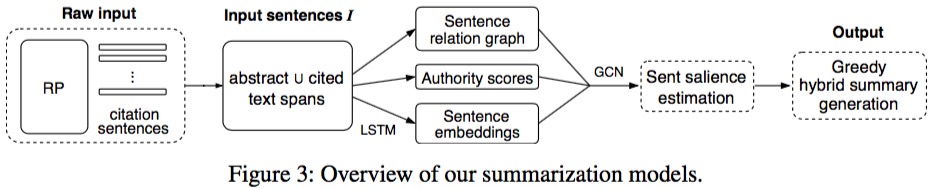
Model
使用LSTM对每个句子进行编码。 句子编码和作者编码作为结点,句子相似性作为边构建图卷积神经网络。 网络模型对句子重要性排序后,用贪心法选择重要的句子、排除重复的句子输出生成的摘要。 参考结果为专家根据这些信息所写的混合摘要。
Experiment Detail
使用ROUGE-2的Recall(2-R),F1(2-F),ROUGE-3的F1(3-F)和SU4-F1(SU4-F)等指标,和之前的数据集及其上最优模型进行了对比。
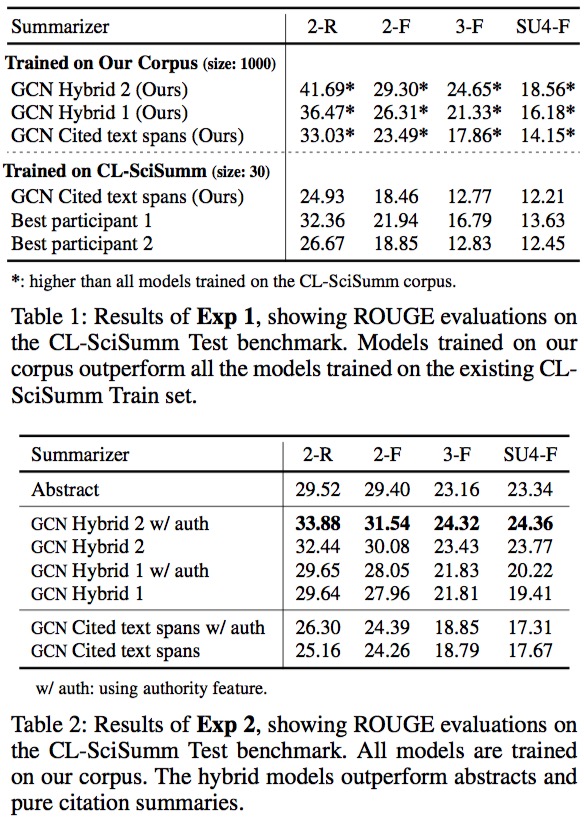 说明了此数据集的价值和方法的有效性。
说明了此数据集的价值和方法的有效性。
Thoughts
本文是检索式摘要模型,将原始句子选择排序输出,1000篇文档可能还不足以支撑生成式的摘要模型,但可以结合预训练模型。 这种数据如果能自动综述应该更有趣。
Author lvcudar
LastMod 2019-09-05