Read Paper 《SoftTriple Loss: Deep Metric Learning Without Triplet Sampling》
Contents
URL: https://arxiv.org/abs/1909.05235
TL;DR
ICCV 2019 参考SoftMax对三元损失改进以实现对多个类中心情况的度量学习。
Dataset
- CUB-2011: 200种鸟类的11788张图。
- Cars196: 196种车的16185张图。
- SOP: 斯坦福在线商品数据集,包含22634种商品的120053张图。
Algorithm
softmax loss也可以视为是一种triplet loss, 只是正样本和负样本分别变成了类内和类间模板。
\( S^{'}_{i, c} = \sum\frac{\exp(\frac{1}{\gamma}X^T_iW^k_c)}{\sum_k \exp(\frac{1}{\gamma}X^T_iW^k_c)} X^T_iW^k_c \)
\( L_{SoftTriple}(X_i) = - \log\frac{\exp(\lambda(S^{'}_{i, y_i} - \delta))}{\exp(\lambda(S^{'}_{i, y_i} - \delta) + \sum_{j \ne y_i}\exp(\lambda S^{'}_{i, y_i}))} \)
这里使用软最大化支持多个类中心但方法来更好的适应同一类别的不同视角样本,比如同一种鸟的不同姿势。
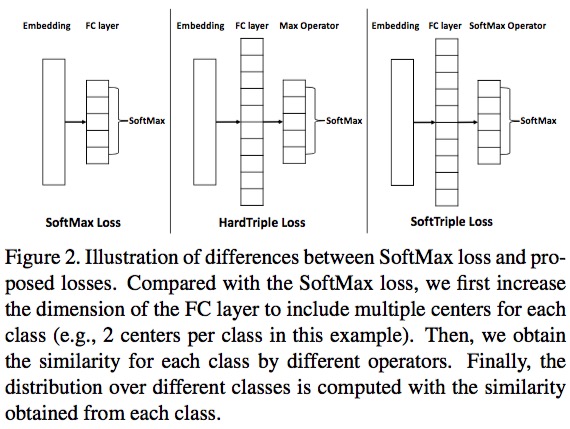
Experiment Detail
基线是SoftMax。
在三个数据集上分别取一部分类别学习表示,在另一部分未用来训练但类别上测试,均比基线和其他方法有提升。
消融实验比较缺乏,公式中包含几个超参——τ、γ和δ, 没有对这两个超参做消融实验, 没有对HardTriple做实验对比。
从实验可以看出,类中心数目的正则化非常重要;本文没有解决如何在开始阶段就自适应的确定类中心数目的问题,CUB-2011和Cars196初始化K为10,到了SOP初始化K为2。
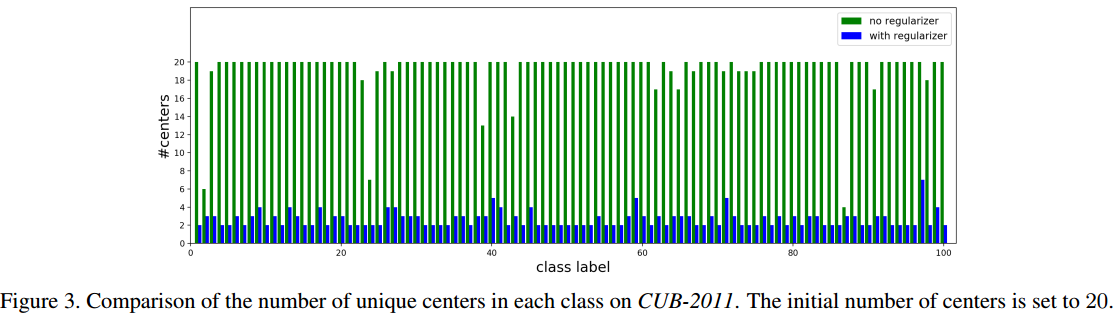
Thoughts
在多个数据集上取得了明显而普遍的提升,但是跨数据集仍然不一定work。 多类中心不实用,对W参数增加太显著了。
Author lvcudar
LastMod 2019-09-12