Read Paper 《Slice-based Learning: A Programming Model forResidual Learning in Critical Data Slices》
Contents
URL: https://arxiv.org/abs/1909.06349
TL;DR
NIPS 2019 提出一种编程抽象方法,用于在不损害整体性能的情况下提高难点部分的效果。比如穿黑衣服的骑车人难以识别,那么可以用一个粗略的方法挑出包含黑衣骑车人的样本(可以有杂质),然后交给框架针对性优化并获得整体提升。
Model
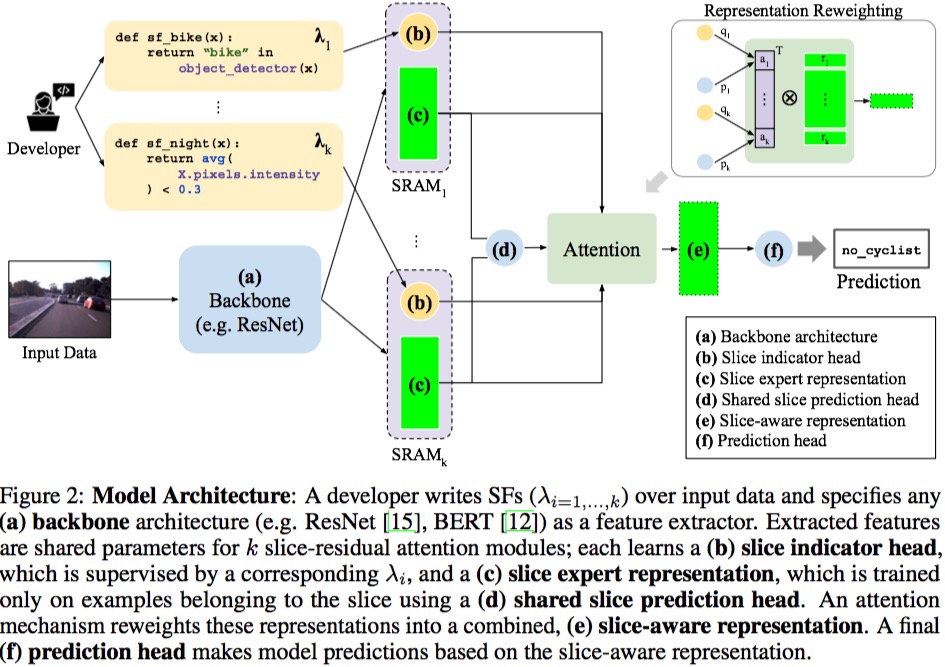 1. 通过基础模型得到数据的表示。
2. 根据切片函数(sf)找到对应的样本及其表示,这里训练模型尽可能找到准确的切片。
3. 对所有对切片表示结果应用注意力得到对这种切片方法敏感对表示,这里训练对切片内对二分类是否准确。
4. 通过最终对预测器得到结果
1. 通过基础模型得到数据的表示。
2. 根据切片函数(sf)找到对应的样本及其表示,这里训练模型尽可能找到准确的切片。
3. 对所有对切片表示结果应用注意力得到对这种切片方法敏感对表示,这里训练对切片内对二分类是否准确。
4. 通过最终对预测器得到结果
Dataset
- 合成数据 >- 二维点集分类,95%线性可分。
- NLU >- CoLA(Corpus of Linguistic Acceptability): 判断句子是否符合语法,包含23种语言。 >- RTE(Recognizing Textual Entailment): 判断一个句子的含义是否和其他文本有关。
- CV >- CyDet(Cyclist Detection for Autonomous Vehicles): 骑车人是否在视频每一帧中出现。
Experiment Detail
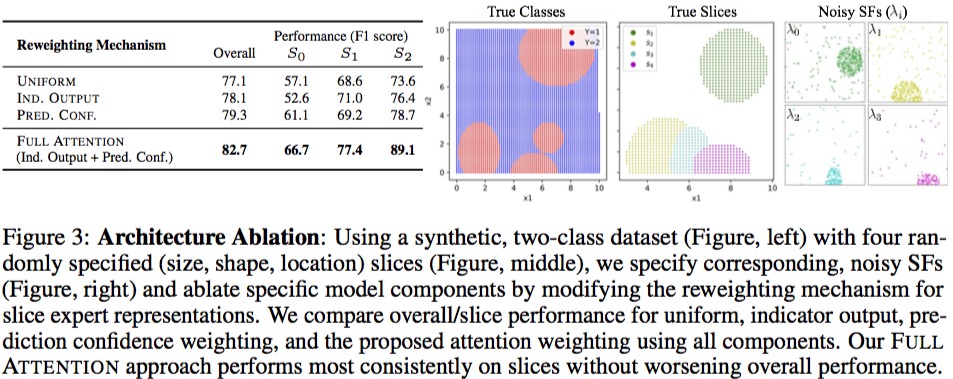
消融实验
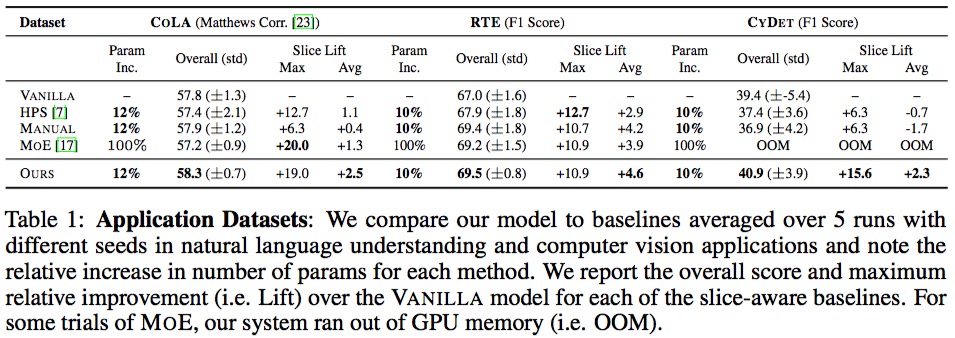
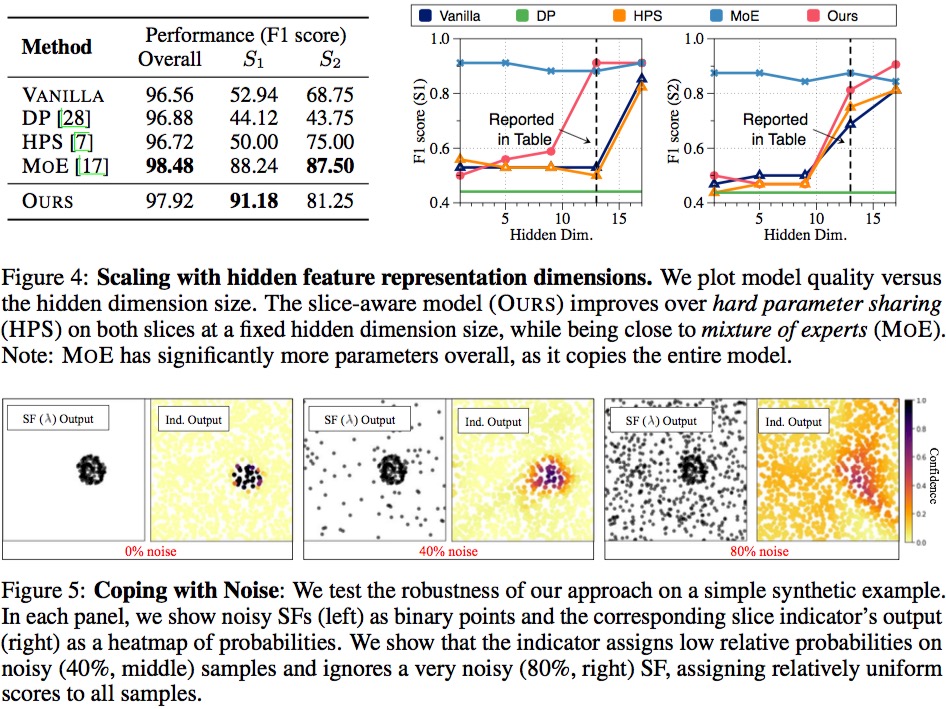 NLP和CV任务对比
NLP和CV任务对比
Thoughts
感觉这能让模型更加容易交互,调动开发者积极性。
Author lvcudar
LastMod 2019-09-16