Read Paper 《Text Length Adaptation in Sentiment Classification》
Contents
URL: https://arxiv.org/abs/1909.08306
TL;DR
ACML 2019 跨长度迁移学习,在影评场景下用短评论训练情感分类模型预测长评论或反之。
Dataset
https://github.com/rktamplayo/LeTraNets
收集自不同领域不同语言的长短评论数据,并人工挑选标注 - MOV_EN 英语影评 - RES_EN 英语餐评 - MOV_KO 韩语影评
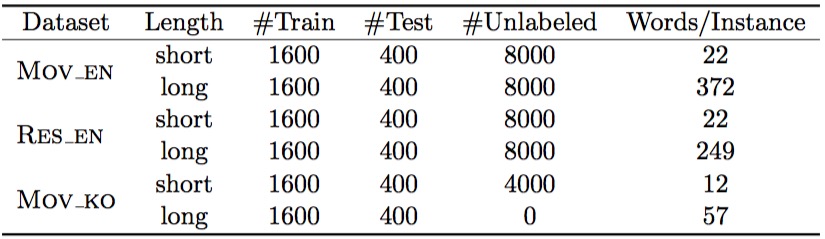
Task
长度迁移相对于领域迁移或语义迁移,具有相同的环境(领域)和语言却有截然不同的长度,及长度不同导致的显著词语丰富度和结构化的不同,带来新的挑战。 相关的跨领域迁移、多实例学习(MIL)和弱监督都不易直接用于长度迁移。 长度的不同对于RNN有着显著的影响,而本文所设计的基线和最优模型也都采用了CNN结构。
Model
本文参考MILNet构建了一个强基线BaggedCNN。
进而集成CNN结构构造了SOTA模型LeTraNets。
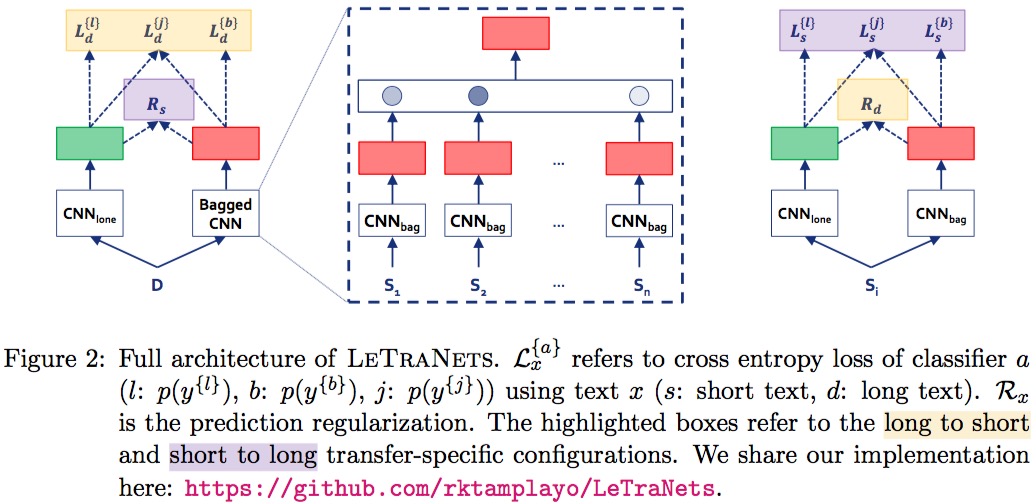 LeTraNets测试的时候将评论分别输入两个网络,长短都输入CNNlong获取整体特征,长评论再输入BaggedCNN获取分段特征,短评论则输入CNNbag获得分段特征,最后将两个输出特征拼接并预测情感分类。
其中CNNlong是一个,CNNbag也只有一套参数。
LeTraNets测试的时候将评论分别输入两个网络,长短都输入CNNlong获取整体特征,长评论再输入BaggedCNN获取分段特征,短评论则输入CNNbag获得分段特征,最后将两个输出特征拼接并预测情感分类。
其中CNNlong是一个,CNNbag也只有一套参数。
模型训练则非常麻烦,因为测试时是另一种长度,所以训练时,长文本将其每段输入BaggedCNN,短文本则随机挑一些情感一致的输入CNNlong。 作者还设计了三种训练策略让网络能够被训练出来: - 联合训练(JT): 采用同一套词向量初始化 - 预测正则化(PR): 用KL散度约束两边CNN单独的预测标签尽可能一致 - 逐步训练(SP): 先预训练每个CNN在整体训练
Experiment Detail
采用GloVe300词向量初始化,对比相关任务的模型取得SOTA,且很多相关人物的模型在本任务不work。
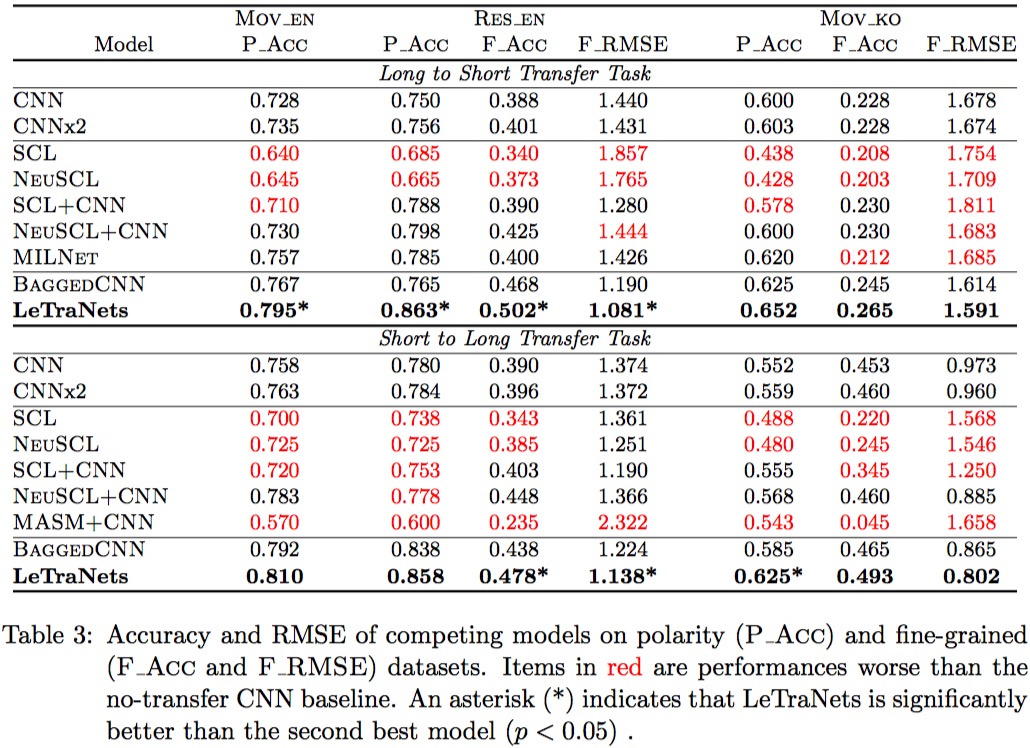
消融实验上度量了迁移率指标,即跨长度错误率/不垮长度错误率,以及三种训练策略的作用。
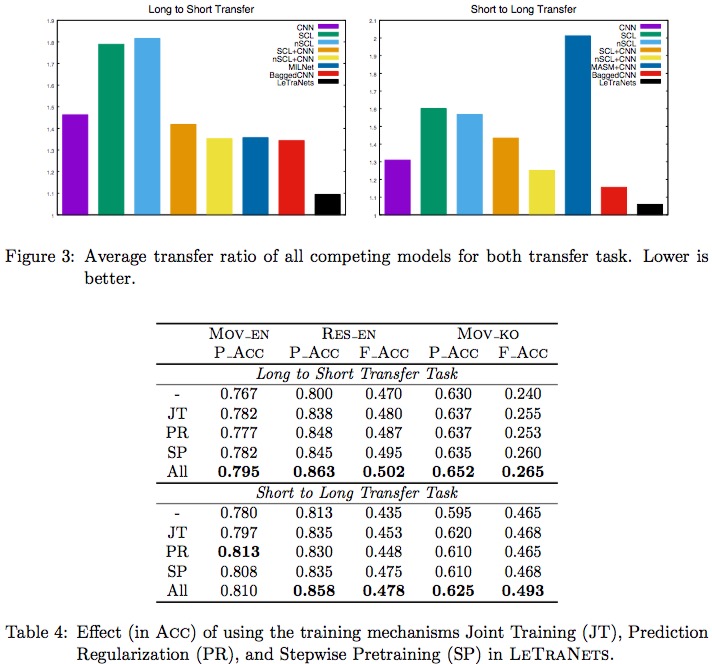
并且还补充验证了,随着长度变化、主题多样化本文的模型都能逐渐显现优势。
Thoughts
消融实验的思路不错,很完整有说服力。 这个网络感觉太麻烦了,而且transfomer类的模型应该具有适应长度的能力,但是缺乏参考。
Author lvcudar
LastMod 2019-09-21