Read Paper 《Talk2Car: Taking Control of Your Self-Driving Car》
Contents
URL: https://arxiv.org/pdf/1909.10838.pdf
TL;DR
一个自动驾驶交互数据集,在街景、自动驾驶场景下,根据视频(雷达)和自然语言输入找出正确对参考对象,如靠近某人或物体停车。 可以看作是视频文本理解任务或者领域VQA
Dataset
http://macchina-ai.cs.kuleuven.be

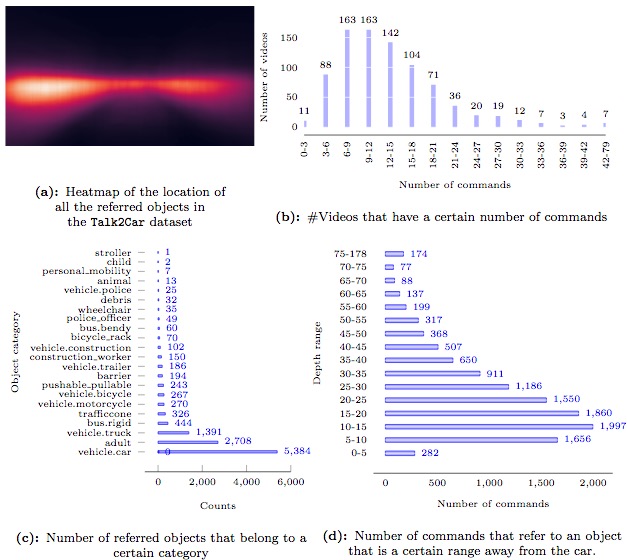
本文的数据集在unScenes dataset基础上构建。
为每一段视频标注尽可能多的指令和参考对象,除了视频还提供雷达等多模态信息。
Method
作者将已有解决方法按是否基于区域候选划分。 候选框统一由SSD512提供,然后为候选匹配指令语义;非候选框的方法由文本理解得到图像中的关注区域。
Model
文章没有提出新的baseline,在随机方法和相关SOTA模型上进行了测试
| Model | Name | Desc |
|---|---|---|
| RNM | Random Noun Matching | 将指令中抽出的名次和所有SSD给出的候选框随机匹配 |
| RS | Random Selection | 随机选择SSD的候选框作为预测 |
| BOBB | Biggest Overlapping Bounding Box | 从测试中SSD输出的候选框中选择与训练集标注重叠最多的 |
| OSM | Object Sentence Mapping | 将SSD+ResNet18得到的候选区域特征和GRU得到的指令特征内积匹配 |
| SCRC | Spatial Context Recurrent ConvNet | CVPR2016 http://ronghanghu.com/text_obj_retrieval/ |
| S-NMN | Stack Neural Module Network | ECCV2018 http://ronghanghu.com/snmn/ |
| MAC | Memory Attention Composition | ICLR2018 https://openreview.net/forum?id=S1Euwz-Rb |
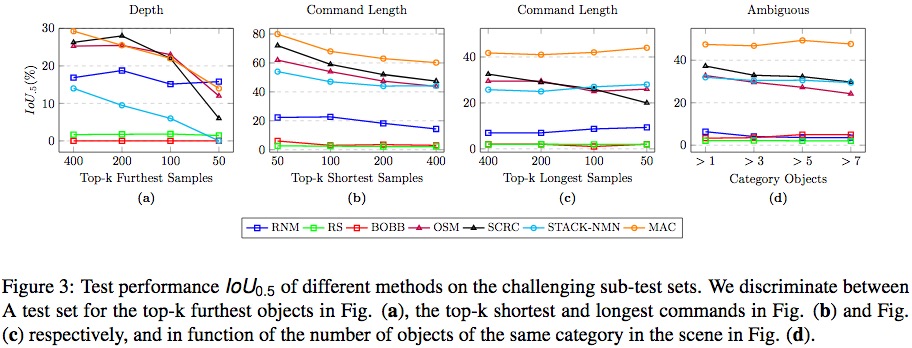
Experiment Detail
Thoughts
类似VQA的寻找参考任务,特定领域数据集,但没有给出加入街景特点的新Baseline。
Author lvcudar
LastMod 2019-09-28