Read Paper 《Is Word Segmentation Necessary for Deep Learning of Chinese Representations?》
Contents
URL: https://www.aclweb.org/anthology/P19-1314
简介
ACL2019 探索神经网络大行其道的时代中文研究中分词的必要性,发现不分词只分字效果近似甚至更好。同时本文列举了大量中文任务数据集。
数据集
| 名称 | 任务 | 描述 |
|---|---|---|
| CBT6 | 语言模型 | 类似PTB,包含正规中文句子 |
| LDC | 机器翻译 | 语言数据联盟中有很多语言类比赛和数据,其中的中英翻译语料作为训练集 |
| NIST_MT | 机器翻译 | 美国标准技术研究院的机器翻译比赛数据作为测试集 |
| BQ | 相似性与复述 | EMNLP2018一篇论文提出的数据集,标注12万中文句子对是否语义相同 |
| LCQMC | 相似性与复述 | ICCL2018一篇论文提出的重复问题数据集,标注句子对是否关心同一个回答 |
| ChinaNews | 文本分类 | 7类中文新闻 |
| Ifeng | 文本分类 | 5类中文新闻的第一段 |
| JD_Full | 文本分类 | 1-5星的京东商品评论 |
| JD_binary | 文本分类 | 京东商品评论忽略3星后分成正负面评论 |
| Dianping | 文本分类 | 大众点评网评论按评级分为正负面 |
- 机器翻译中LDC选择了这些任务的数据: LDC2002E18, LDC2003E07, LDC2003E14, Hansards portion of LDC2004T07, LDC2004T08 and LDC2005T06; NIST_MT则选取了2002-2008年的数据。
- 语义相似度和复述任务的两个数据集都类似SNLI,分别来自EMNLP2018的《The bq corpus: A large-scale domain-specific chinese corpus for sentence semantic equivalence identification》和ICCL2018的《Lcqmc: A large-scale chinese question matching corpus》。
- 文本分类的数据集来自参考文献《Which encoding is the best for text classification in chinese, english, japanese and korean?》的整理。
算法与模型
这篇论文主要讨论分词的必要性,主要是对神经网络模型采用分词或每个字作为单独符号向量进行对比,同时对比多种分词方法。
实验与对比
语言模型
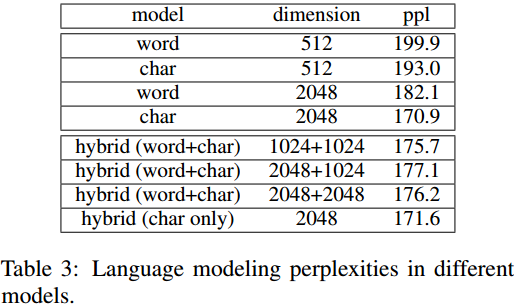
基于字的方法取得了更低的困惑度,字词混合也不如纯字。
机器翻译
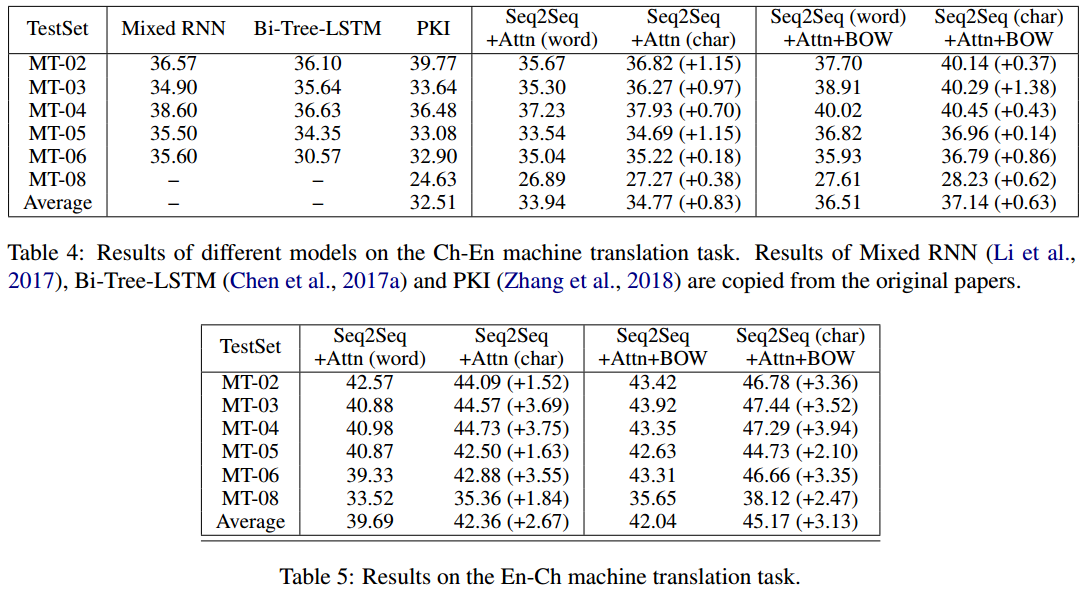
同样序列到序列模型基于字的方法普遍更优,而且基于字的朴素模型堪比基于分词的其他最新研究。
句子匹配与复述
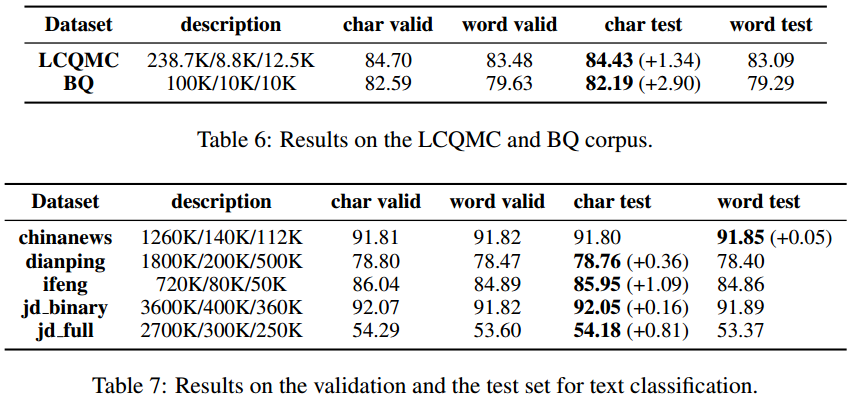
以这两个数据集SOTA论文——IJCAI2017《Bilateral multi-perspective matching for natural language sentences》的BiMPM为基线,均取得提升。
文本分类
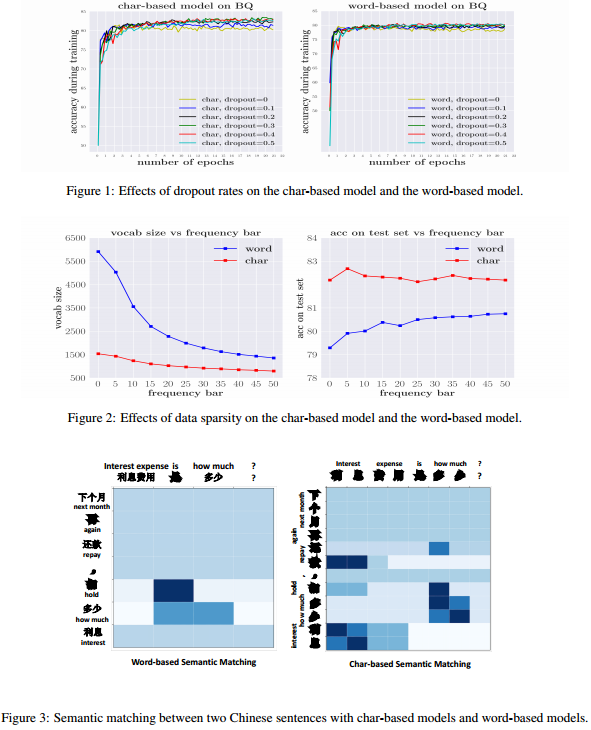
除了ChineseNews之外其他5个数据集都取得提升。
消融分析
作者还总结了不分词直接基于汉字的优势: 1. 更均衡的字典,不同字出现频率比不同词要均匀。 2. 减少字典外符号,有些词可能很罕见但是组成它们的字却是常见的,可以减少unk的情况。 3. 减缓过拟合,因为每个字在训练样本中出现次数差异不大,能更均匀的让模型学习其表示。
思考
这篇论文系统的研究了神经网络和深度学习兴起后对分词任务的影响,并证明了神经网络已经可以自行克服是否分词对语义学习的影响。 同时,这里使用的数据集为中文研究提供了良好的基准。
Author lvcudar
LastMod 2020-01-19