Read Paper 《Neural Syntactic Preordering for Controlled Paraphrase Generation》
Contents
URL: https://www.aclweb.org/anthology/2020.acl-main.22 https://github.com/tagoyal/sow-reap-paraphrasing
简介
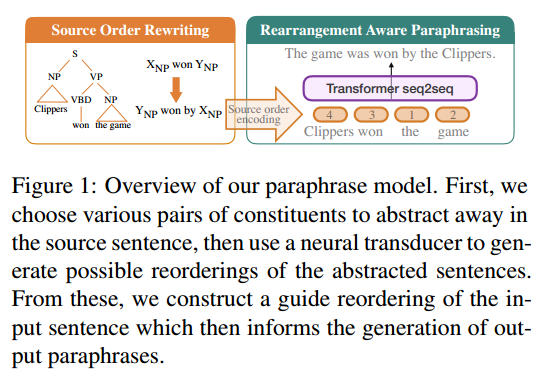
ACL2020 引入输入重排序的方法,通过排序多样性生成多样化复述,并且提升生成质量。
背景
- 复述生成是一个多方面的问题包括词和短语的替换、内容位置的重新排序、高级重构主题变化和语态变化等。
- 最近复述生成在大规模数据集、深度生成模型、对抗样本等方面取得了很多的进展。
- 之前关于内容位置重新排序的复述生成工作是依赖手动设计的。
- 用语义解析模板调整语句位置是固定的不能灵活面对多样化的句子,实现多样化的生成。
- 这里讨论的复述生成都是句子级别的。
动机
- 依靠单一的序列到序列模型难以产生足够多样化的复述生成,尤其是难以改变句子结构。可以借鉴机器翻译的思路输入生成模型前重排输入句子结构以利于生成。
- 传统的语法解析方法结构固定,得到的重排方式也固定,可以用深度神经模型得到更灵活多样的可行排序。
数据集
ParaNMT-50M 一个基于捷克语和英语翻译数据构建的大型复述数据集。 由五千万规模的复述句对组成。 有充分的不同语序的句对,长短不同的复述。
算法与模型
- 将通常一阶段的复述生成分成两个阶段:
- 第一个阶段对输入句子重新排序得到重排后的位置信息作为条件。Source Order reWriting
- 第二个阶段根据重排后的位置信息进行条件生成得到复述句子。REarrangement Aware Paraphrasing model
- 第一个阶段对输入句子重新排序得到重排后的位置信息作为条件。Source Order reWriting
第二阶段位置敏感的复述(REAP)生成由普通序列到序列的复述生成模型改进而来。 这里将第一阶段得到的重新排序的结果,进行位置编码添加到编码器最后一层输出。 实验证明这样就可以引导解码器按照给出的顺序条件先后注意输入的不同部分。 即解码器在生成clippers won相关内容前先生成the game相关内容。
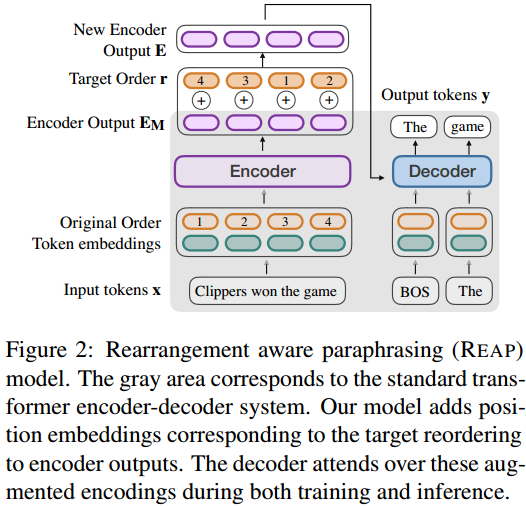
训练时每个复述句对作为输入x和输出y 用对齐的方法为y的每一个词算出在x中的位置作为生成的顺序条件r 实际测试的时候r由SOW模型给出。 即训练的时候和普通的seq2seq模型训练没什么区别。 训练时额外条件r也是离线计算好的。
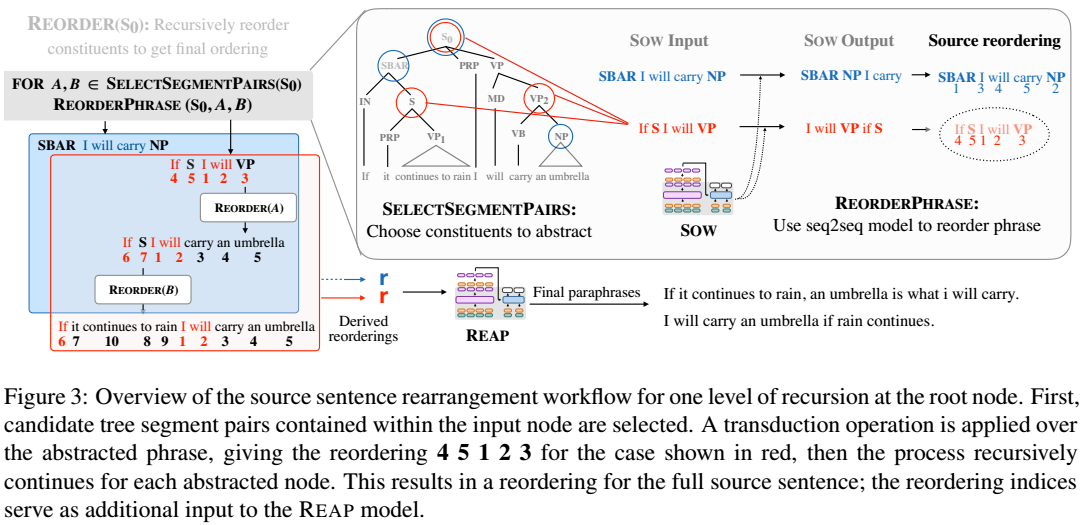
第一阶段重排过程: 首先得到输入句子的语法树。 相同句法成分的短语用句法符号替换,上图红圈那种,不是叶节点。 枚举任意两个非叶子句节点,可通过SOW保持或交换他们得到新的顺序z,及其对数概率作为score(z)。 基于z递归得到交换的两个子句各自的重排可能。 最终拼接得到整个句子的一个重排结果。 最后保留分数最好的k歌重排结果的位置信息。

SOW模型也是一个Seq2Seq模型。 O指示保持短语顺序还是翻转,只会有两个非零值,指示待处理的两个短语A、B。 目标输出是O所指示的重排后的样子。 即SOW根据给出的输入x和是否交换的决策O,输出结果y和分数PPL。
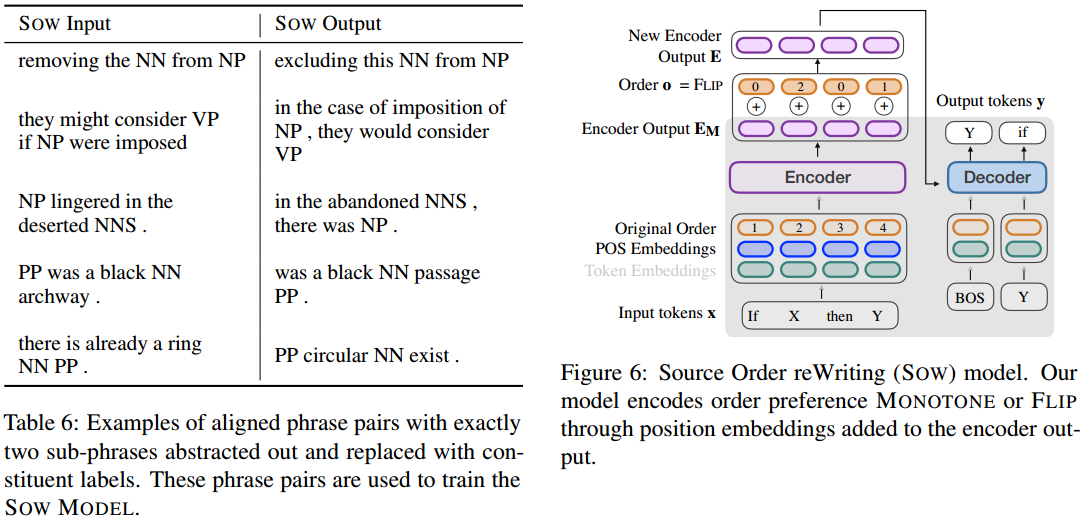
SOW的训练数据从ParaNMT50M中选择对齐分数比较高的作为训练样例,大约350K。 将这些句对按照排序过程代入训练SOW模型。 期望SOW能为重排决策给出合理的分数。

评估
多样性选择统一输出十个句子,质量选择最好的输出。
比基线多样性模型更准确,比普通Transformer基线更多样。
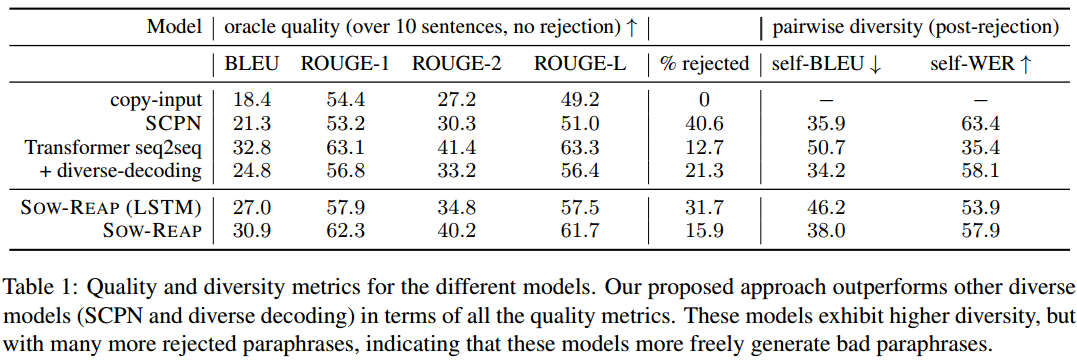
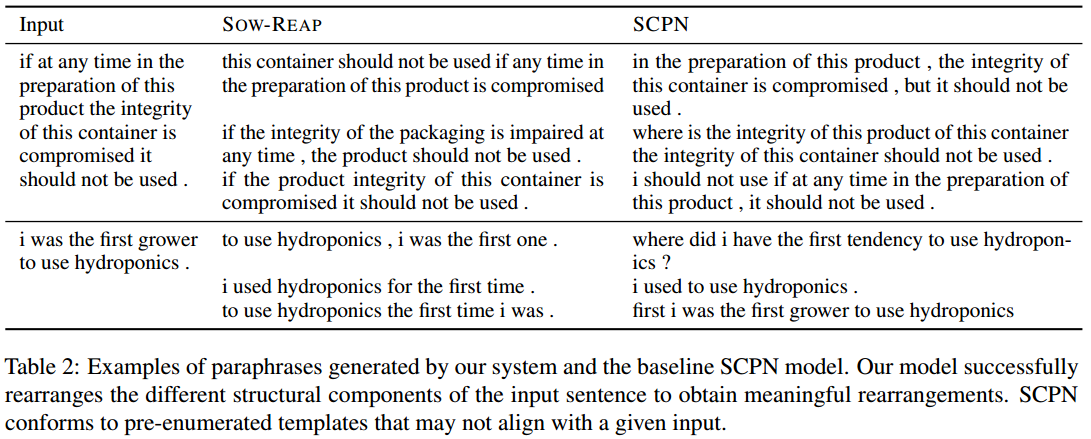
人工评估的结果也是质量和多样性比较均衡。
分析
SOW的输出是有意义的,比随机和原序的十个候选更能覆盖到参考答案。
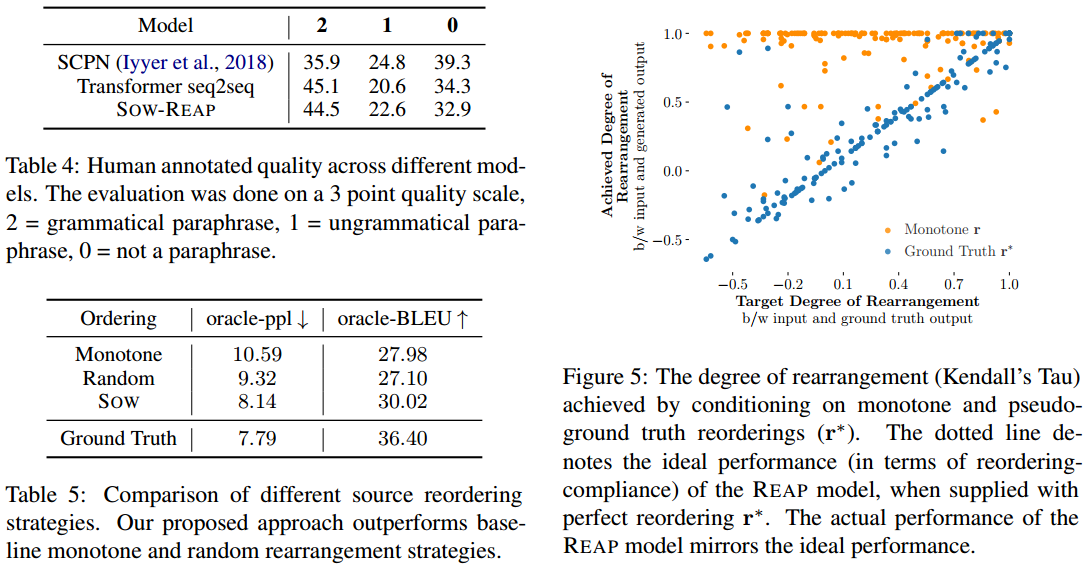
图5分析了REAP是否遵循了位置指导,横轴输入和参考序列相关度,纵轴输入和生成序列相关度。 保持原序条件下不论参考怎样生成结果总是基本和输入同顺序。 采用真是顺序作为条件,REAP生成和输入的顺序差异 与 参考和输入的顺序差异 差不多。
总结
通过多样化的句法指导生成多样化的复述是可行的,而且能得到质量和多样性的均衡。 SOW对顺序的打分是有意义的。 REAP能比较好的遵循给出的顺序位置条件。 十个句子的多样性评测还是很不错的。
Author lvcudar
LastMod 2020-07-26