Read Paper 《An End-to-End Generative Architecture for Paraphrase Generation》
Contents
URL: https://www.aclweb.org/anthology/D19-1309
简介
EMNLP2019 一种端到端的复述模型,将使用LSTM的条件变分自编码器作为生成对抗网络的生成器,达到了SOTA。
数据集
| Name | Task | Link | Desc |
|---|---|---|---|
| Quora | 复述生成 | https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs | Quora重复问题数据集,超过40万 |
| SST | 语义分析 | https://nlp.stanford.edu/sentiment/ | 斯坦福情感分析数据集,正负面共五类约20万句 |
本文按照2016年的《Neural paraphrase generation with stacked residual lstm networks》采用4个数据集,其中Quora被划分为3个分别是50k、100k、150k。
算法与模型
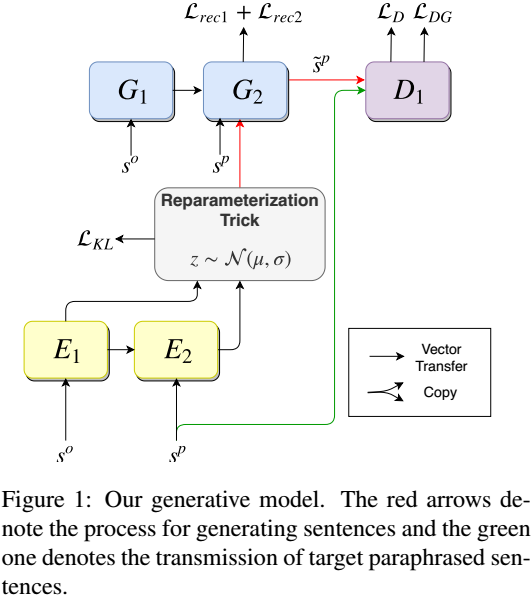
模型中的网络模块均采用LSTM。 从编码器得到假设为高斯分布的z的均值和方差。 解码器G1、G2是一个seq2seq过程,G1输入原句得到中间状态作为G2LSTM的初始隐状态(H,C),G2则一个接一个预测词,如同机器翻译一般。 鉴别器用LSTM判断输入的句子是参考还是生成的。
本文的主要创新在于VAE部分计算图有两条路径。 1. 将原句和目标句分别输入E1、E2得到潜在分布z1,将从z1采样的变量拼接到G2的输入,完成解码得到输出sp1。 2. 模拟测试环境,只将原句输入E1得到潜在分布z2,将从z2采样的变量拼接到G2的输入,完成解码得到输出sp2,并将sp2送入鉴别器。
两条路径都是训练时的,测试采用第二条路径。 损失方面最小化z1和z2的KL散度,最小化两条路径输出和目标句的差异,只有sp2送入鉴别器和目标句计算GAN的损失。 最小化z1和z2的KL散度在利用参考强化语义编码的同时缓解了训练和测试的流程偏差。

实验与对比
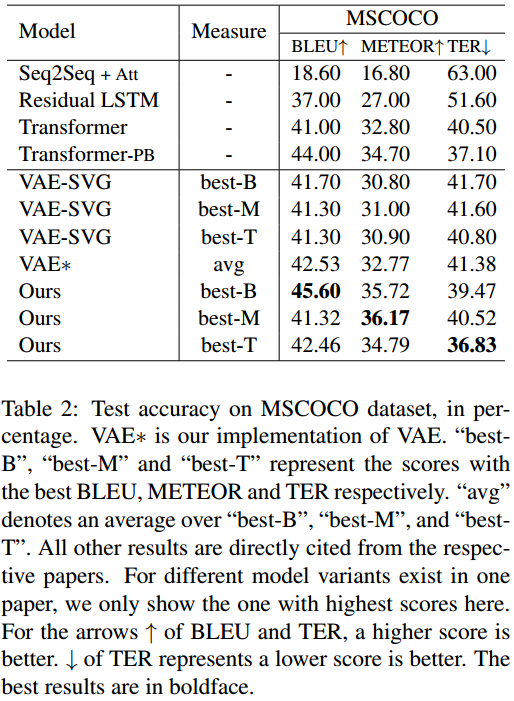
在MSCOCO和Quora的三种划分上,本文的模型都超越基线并在BLEU、METEOR、TER上实现了最优。
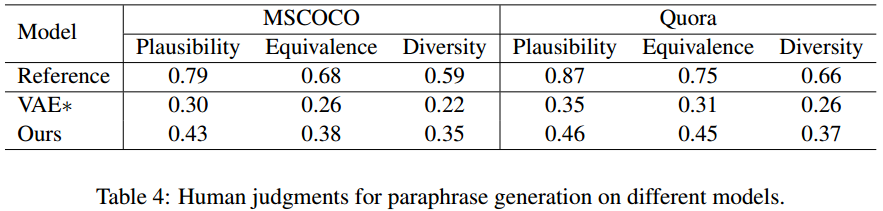
作者还用人工评判了真实性(语法正确)、一致性(含义不变)、多样性(备选结果多样)。
从测试集各随机采样100个,组成真复述对和生成复述对在亚马逊众包平台进行评测,得到了显著性p值小于0.01。
思考
aclweb上下载的版本竟然在第一部分介绍中有段落划分的格式错误。 结果非常好,也许多样性应该用mBLEU之类指标测测,但是没查到开源代码。 两条路径分别进行强监督和模拟测试,用于机器翻译也许能达到加快训练且克服偏差的效果。
Author lvcudar
LastMod 2020-02-06