Paper Read 《Bridging the Gap between Training and Inference for Neural Machine Translation》
Contents
URL: https://www.aclweb.org/anthology/P19-1426
简介
ACL 2019 最佳长论文。 使用新的训练方法跨越神经机器翻译训练和测试解码输入不同和过渡矫正为例句的问题。 即从之前输出,真实参考和其他例句中选择训练时的输入,而不只是用一句参考。
数据集
- NIST(Zh-En): 美国国家标准技术研究所在2002-2006年的机器翻译数据
- WMT14(En-De): 统计机器翻译研讨会,每年举行新闻翻译比赛并公开数据 http://www.statmt.org/wmt14/translation-task.html
问题
- 曝光偏差: 训练的时候有参考句,预测错误可以把正确的参考作为下一步的输入,但是测试的时候一旦错误就会累积。
- 过渡矫正: 翻译可以有多种,但是参考只有一个,这样训练久了,模型就过渡的倾向参考而排斥了其他答案。
方法
解决以上问题,作者在训练的时候提供除了真实参考以外的作为解码某一步的输入。
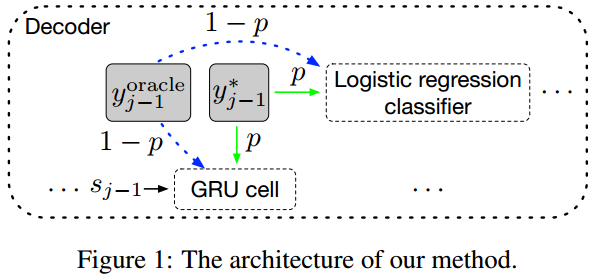
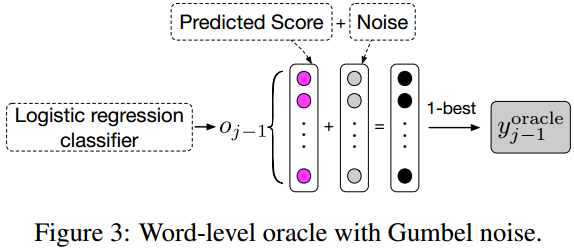
- 字级别可以直接把解码器前一步输出作为下一步输入,也是之前常用的方法,这里作者选择解码时加入噪声提高鲁棒性。
- 句子级别则先用束搜索得到多个句子,选择和参考局bleu最高的作为新的参考,则每次解码的输入可以来自答案、前一步输出或新参考的相应位置。
新参考可能和答案不一样长,这里需要略微调整解码步骤。
- 如果在答案长度前输出结束符,则采用第二可能的词;
- 如果在答案长度处最大概率不是结束符,则使用结束符号并且使用结束符的概率。
当然刚开始训练的时候新参考没什么意义,所以用随时间减小的概率p来决定是否选择答案作为输入。 \( p = \frac{\mu}{\mu + \exp(e / \mu)} \)
模型
基于fairseq改写。 RNN采用双层GRU。 Transformer使用fairseq的默认设置。
实验与对比
在两个数据集的实验都取得了明显的提升。
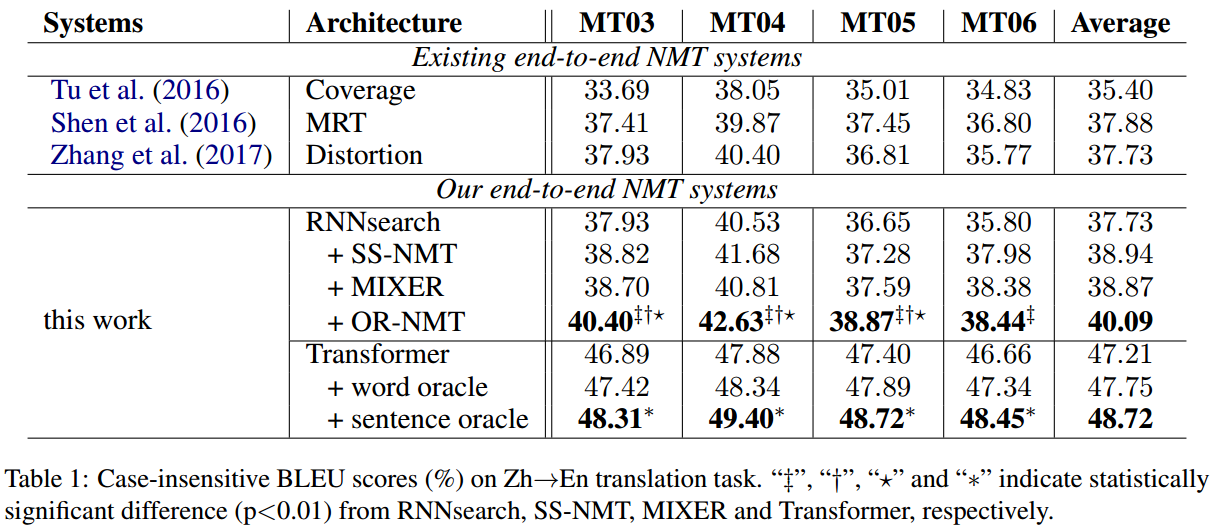
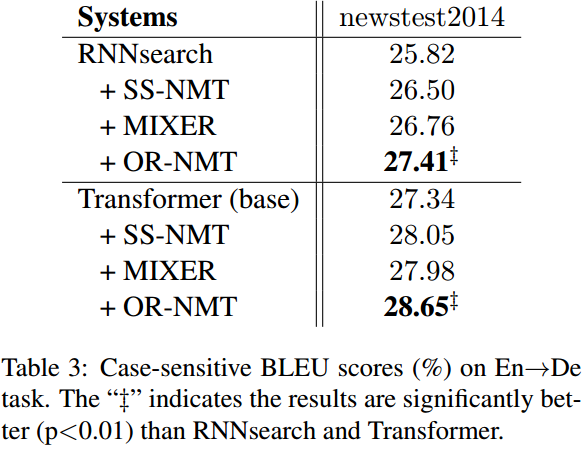
噪声也是很有必要的。

思考
这种自己生成参考句的方法对于类似的序列任务都是有启发的。
为什么不用wmt17年的新数据呢?为了便于对比? 没有列出模型参数或开源代码,也许该看看补充材料。
Author lvcudar
LastMod 2019-10-25