Read Paper 《Controlling Output Length in Neural Encoder-Decoders》
Contents
URL: https://www.aclweb.org/anthology/D16-1140 https://github.com/kiyukuta/lencon
简介
EMNLP2016 提出并对比了4种控制RNN摘要任务生成长度的方法,两种基于学习的方法能够不损失ROUGE。
数据集
参考A Neural Attention Model for Abstractive Sentence Summarization 使用了同样的训练集Annotated English Gigaword和测试集DUC2004Task1。
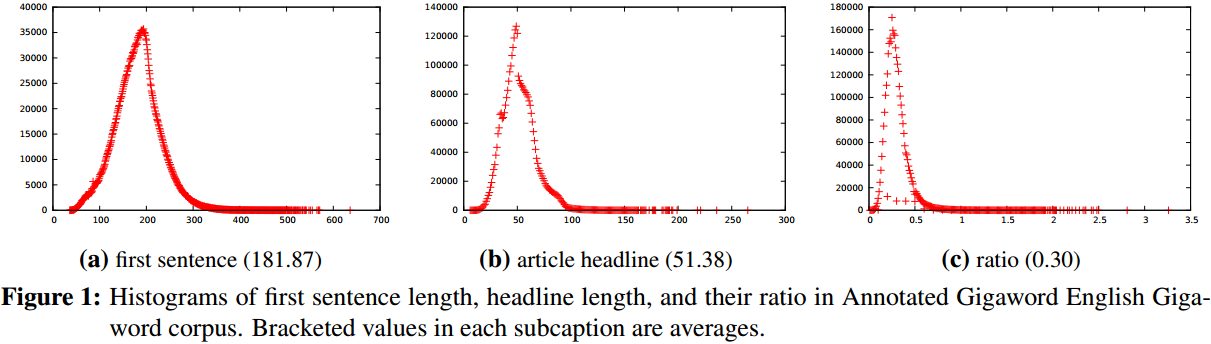
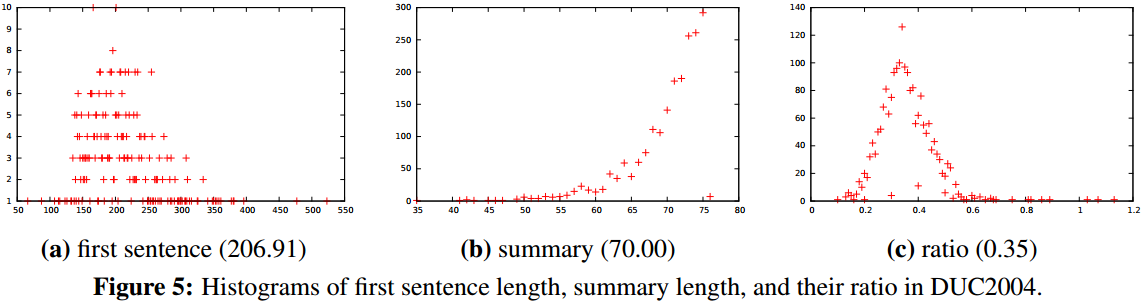
模型
基本模型使用经典的注意力RNN编解码器。
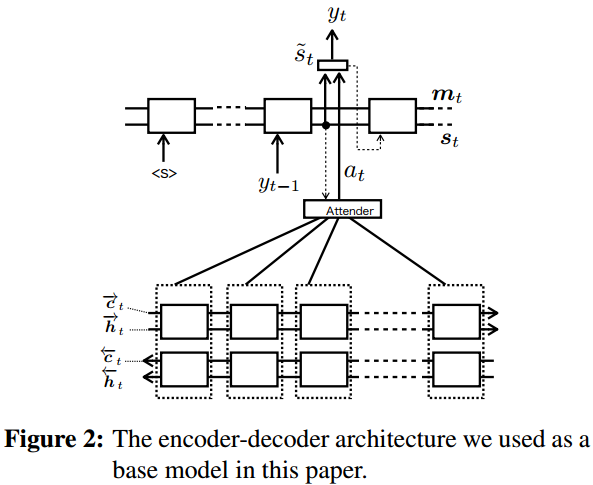
编码器使用双向LSTM。
解码器使用单向LSTM,并配合15年的经典attention。
解码时使用束搜索方法。
损失函数采用最大对数似然:
\( L_t(\theta) = \sum\limits_{(x,y) \in D} \log p(y|x;\theta), \)
\( p(y|x;\theta) = \prod\limits_t p(y_t|y_{
算法
控制长度有两种基于解码的方法和两种基于学习的方法
- 固定长度: 将解码时EOS符号的概率调整为负无穷,束搜索到指定长度。
- 固定范围: 束搜索时丢弃那些不在指定范围输出EOS符号的结果。
- 长度编码: 为每一种长度学习一个编码,具体是在解码每一步输入中拼接剩余长度对应的长度编码。
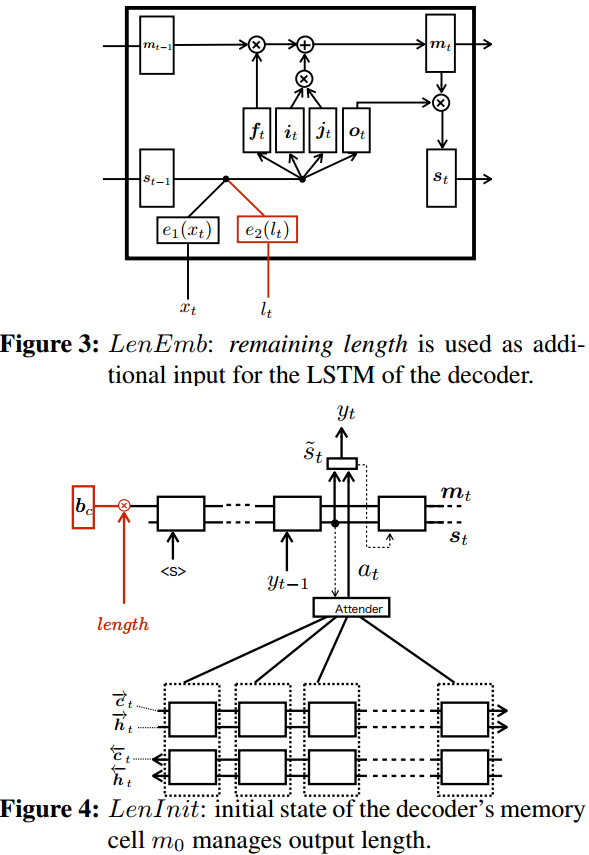
- 长度初始化:只在解码开始时用长度编码作为初始状态的一部分,不再每布输入。
实验与对比
统一使用Adam优化方法和ROUGE指标。
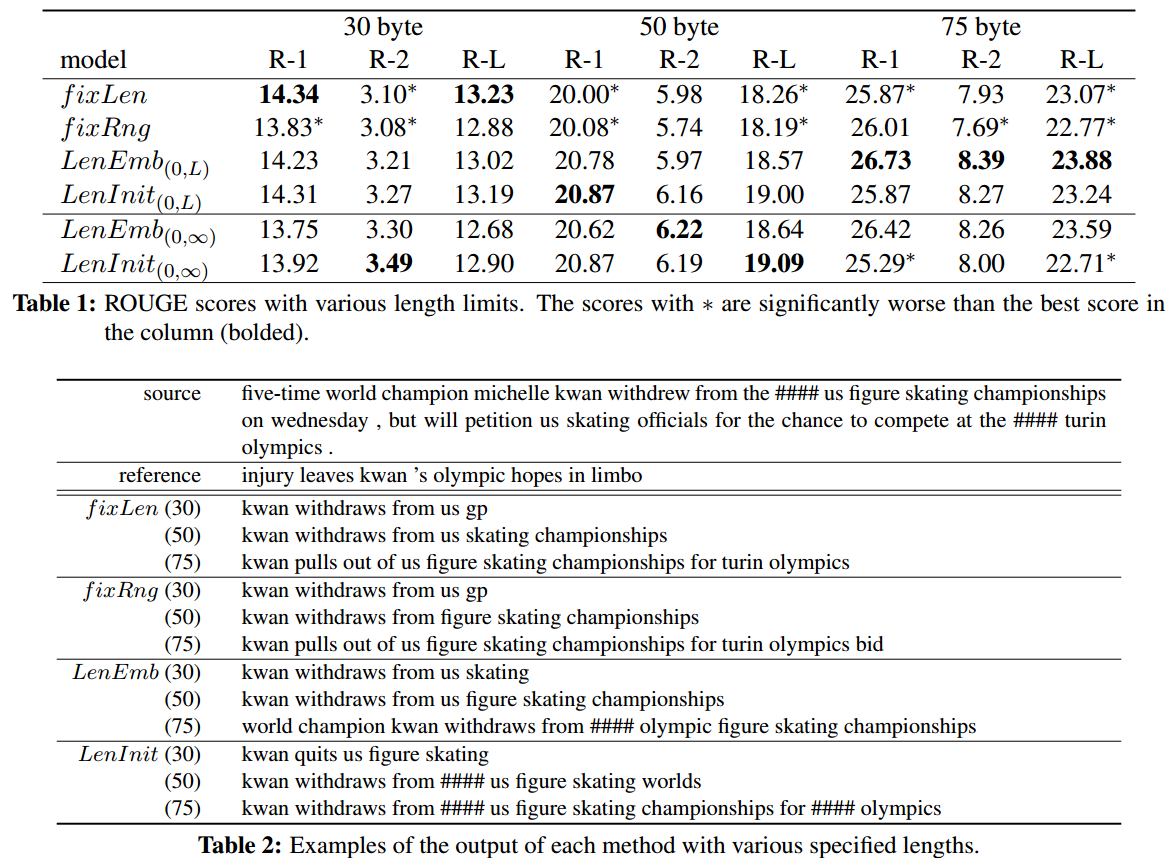
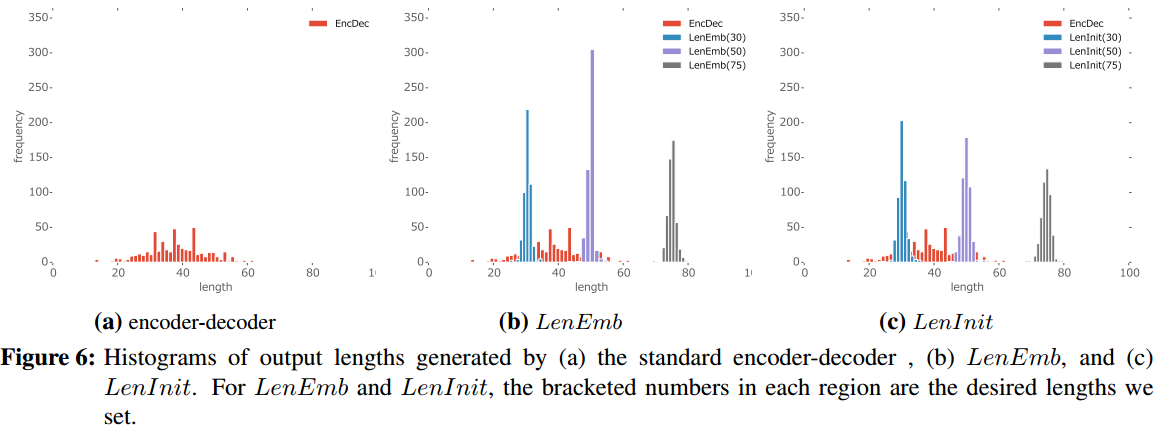
思考
控制长度的摘要可用于定制摘要,但是这缺乏足够的标注数据来验证。 比较好的效果应该是有不同长度参考摘要的数据,实验模型是否能在缩短时保留必要的部分,而加长时能概括出更多内容。 对长度编码的学习对于Transformer类模型和位置编码结合应该可以做很多事。
Author lvcudar
LastMod 2019-11-04