Read Paper 《Controlling Length in Abstractive Summarization Using a Convolutional Neural Network》
Contents
URL: https://www.aclweb.org/anthology/W04-1013
简介
EMNLP 2018 卷积型序列到序列模型控制长度的方法。
模型
基本模型是2017年facebook提出的基于CNN的序列到序列模型。
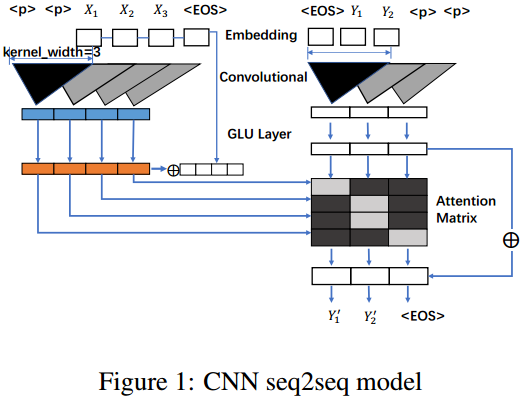
算法
为了控制长度在基础模型的解码器部分进行了用于控制长度的修改。
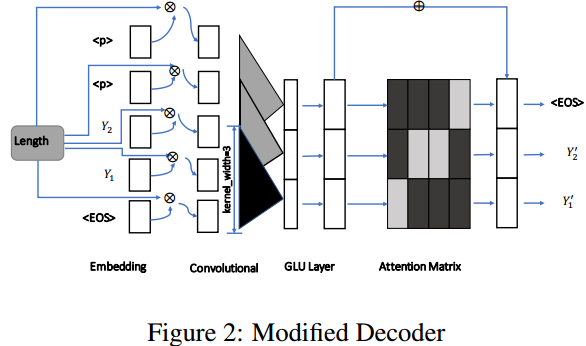
数据集
| Name | Link | Desc |
|---|---|---|
| DMQA | https://cs.nyu.edu/~kcho/DMQA/ | 一个问答基准数据集 |
| TAC | https://tac.nist.gov/data/index.html | 语义相似性数据集 |
实验与对比
Metric
既然进行了长度控制,那么除了使用ROUGE评估准确性,还进行了语义相似的评估。
\( sim = \frac{1}{n} \sum_{i=0}^{n} \frac{y_i * y'_i}{||y_i|| * ||y'_i||}, y_i\text{是摘要的词向量}\)
作者指出相似性比ROUGE更能反映结果。
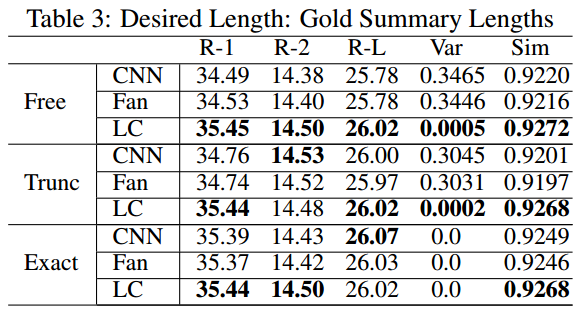
Method
- Free: 给出参考长度N,各个方法自然生成到EOS。
- Trunc: 各个方法如果生成到第N个词没有EOS则强行停止。
- Exact: 生成N个非EOS词。
Experiment
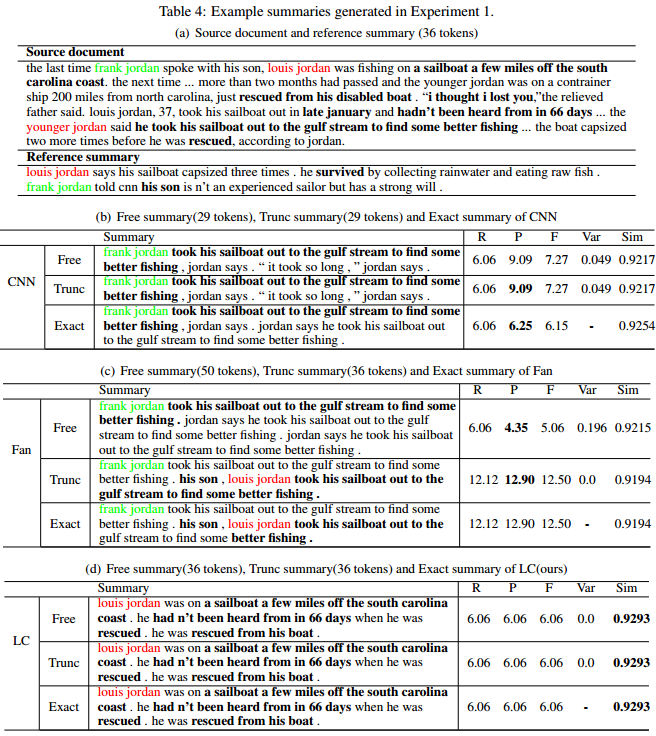
- 按照真实结果的长度生成
- 按照设置的长度生成
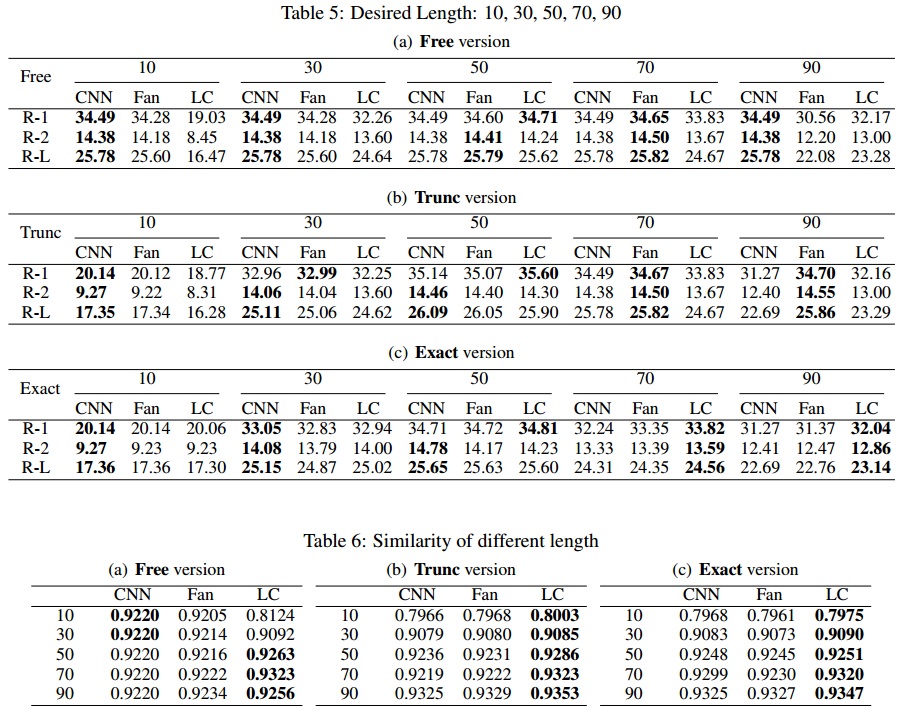
- 这里似乎缺少第三个小标题,这个是统一所有长度(不按照参考长度的范围划分)生成比较相似性。
思考
这个考虑长度的方法也太粗暴了,果然被后人用Transformer上通过位置编码长度控制超越。 作者引用的人工评估在摘要方向的缺陷可以成为优化工作量的好说辞。 这个问答数据集是怎么做的摘要评估呢?原文的数据和代码下载链接不可用了。 实验感觉有些混乱。
Author lvcudar
LastMod 2019-11-26