Paper Read 《Pun-GAN: Generative Adversarial Network for Pun Generation》
Contents
URL: https://github.com/lishunyao97/Pun-GAN
TL;DR
使用GAN生成有歧义的话语
Dataset
训练采用三部分数据,标注词语含义的SemCor、维基百科上的多含义条目、模型生成的数据。 测试采用SemEval2017Task7的数据。
Model
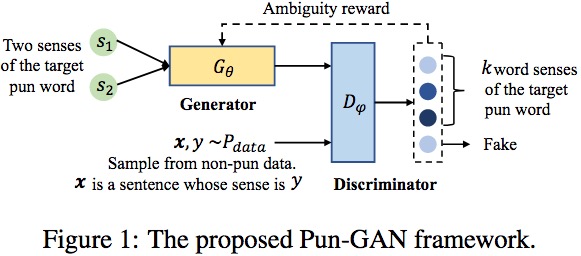 模型以有歧义的词的两个意思为输入尝试生成一个包含这个词且能表达这两个意思的句子,鉴别器则鉴别一个句子中目标词的含义是什么或是有歧义。
模型以有歧义的词的两个意思为输入尝试生成一个包含这个词且能表达这两个意思的句子,鉴别器则鉴别一个句子中目标词的含义是什么或是有歧义。
本文的创新在于设计了一种强化学习的奖励 $r = \frac{D_\phi(s1|x) + D\phi(s2|x)}{|D\phi(s1|x) - D\phi(s_2|x)| + 1}$ 来通过策略梯度优化生成器。 考虑缺乏大规模语料的问题,鉴别器采用半监督的方式训练优化。 即对有标注的数据精细分类,无标注的只区分是否有歧义。
Experiment Detail
效果似乎不错,挺通顺的。

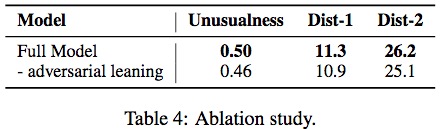
对抗训练能使得歧义更明显。
Thoughts
GAN策略能奏效,也许可以试试VAE。
Author lvcudar
LastMod 2019-10-26