Read Paper 《Doc2EDAG: An End-to-End Document-level Framework for Chinese Financial Event Extraction》
Contents
URL: https://www.aclweb.org/anthology/D19-1032/ https://github.com/dolphin-zs/Doc2EDAG
简介
EMNLP2019 用中国金融公告构建文档级别的事件抽取数据集,带来跨句子甚至跨文档实体和事件抽取的挑战,并提出一种端到端(文档到基于实体的有向无环图)的基线,以及三个子任务(实体抽取、事件检测、格式化填充)。
数据集
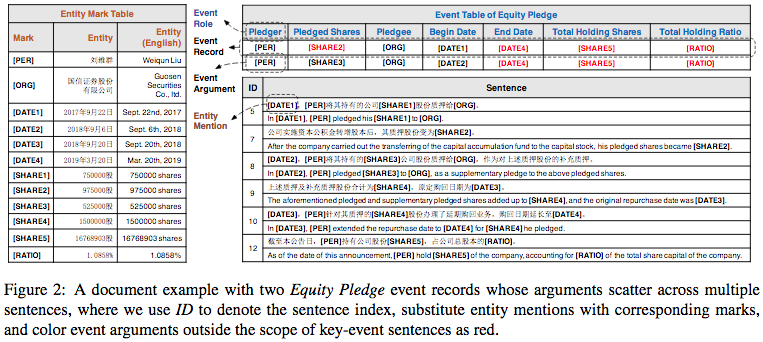
数据集是金融公告文档和对应的数据表格形式。
先考虑远程监督,标注相关句子,然后将同一实体标记为一个ID并填如表格中。
与传统句子级数据不同,没有标注触发词,因为在新的挑战中不应该使用它。
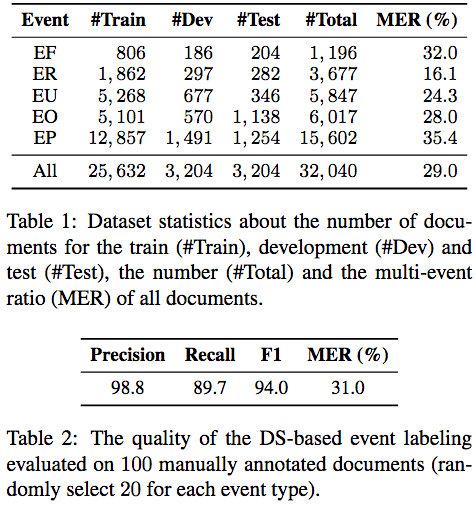
 数据集体积不错34.5MB
数据集体积不错34.5MB
数据集主要关注股票冻结(EF),股票回购(ER),股票超重(EU),股票超重(EO)和股票质押(EP)五类事件。
模型
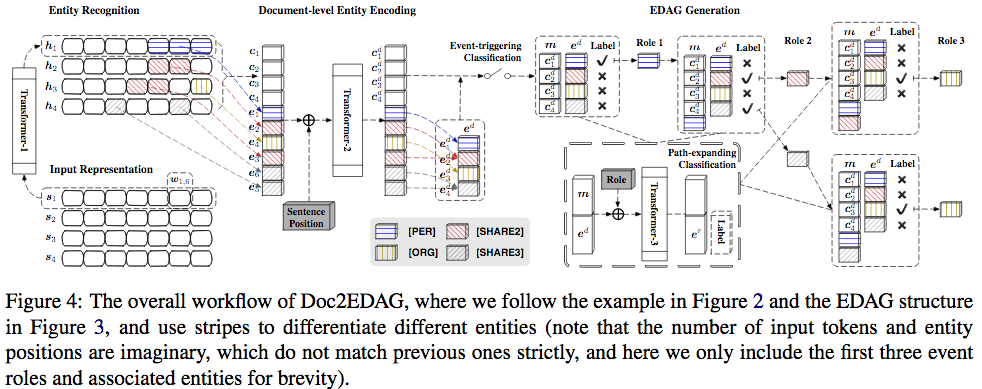
Doc2EDAG的关键思想是将表格事件记录转换为基于实体的有向无环图(EDAG),并让模型学习器根据文档级上下文生成此EDAG。
首先是文档表示为句子的序列,并识别实体。 实体识别基于双向LSTM条件随机场,但是把LSTM换成了Transformer,还可以用BERT。
文档级实体编码: 1. 对每个实体覆盖的不同长度的tok用最大池化获得固定长度对句子级实体编码,同时对句子整体用最大池化获得句子编码。 2. 为上一步的实体编码和句子编码加入位置编码后通过Transformer模型沟通信息,然后对同样名称对实体编码做最大池化获得文档级实体编码。
句子编码做最大池化然后可以通过分类器决定是否触发某种事件。
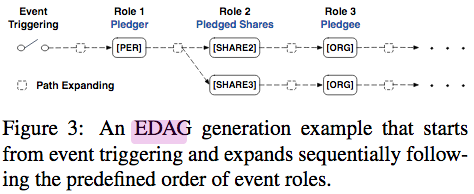 > 基于实体的有向无环图(EDAG)生成:
> * 手动为事件定义实体对顺序。将每个表格中条目表示成实体对链,缺失项为特殊空节点。将相同前缀对链合并构成EDAG。
> * 推理的时候事件的触发作为初始节点,然后不断尝试向其他实体扩展,如果没有合适的实体可以用空节点代替,尝试生成DEAG。
> * 采用记忆机制记录经过的节点避免形成环。
> * 扩展路径的时候,对每一个新实体与记忆一同输入Transformer模型再分类决定是否扩展。
> 基于实体的有向无环图(EDAG)生成:
> * 手动为事件定义实体对顺序。将每个表格中条目表示成实体对链,缺失项为特殊空节点。将相同前缀对链合并构成EDAG。
> * 推理的时候事件的触发作为初始节点,然后不断尝试向其他实体扩展,如果没有合适的实体可以用空节点代替,尝试生成DEAG。
> * 采用记忆机制记录经过的节点避免形成环。
> * 扩展路径的时候,对每一个新实体与记忆一同输入Transformer模型再分类决定是否扩展。
目标函数由事件触发的交叉熵损失、路径扩展对于每个新实体的交叉熵损失、EDAG结构差异损失组成。
整体流程如下图,文中还提到了一些训练技巧。
实验
这里选择了DCFEE作为基线进行了对比,并对本文对新数据集和任务进行了两种修改。是有明显优势的。
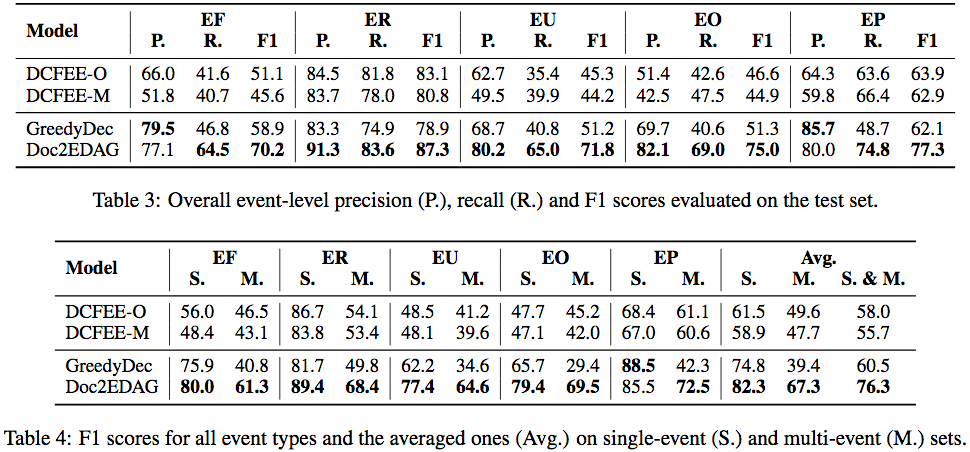 为了说明端到端对必要性,贪婪解码不生成EDAG而是贪婪填充每一个事件。
另外对于Doc2EDAG的每一部分进行了消融实验。
为了说明端到端对必要性,贪婪解码不生成EDAG而是贪婪填充每一个事件。
另外对于Doc2EDAG的每一部分进行了消融实验。
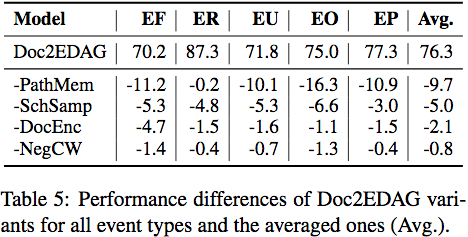
思考
开源很有诚意,甚至包含复现所有实验的脚本,依赖的包也不多,虽然我还没复现。 这算是NLG方面流行的data2text的反向任务。 也许能用图网络改善一下。
Author lvcudar
LastMod 2019-12-07