Read Paper 《Hierarchical Neural Story Generation》
Contents
URL: https://www.aclweb.org/anthology/P18-1082
简介
ACL2018 从reddit论坛收集根据提示写故事的数据集,并通过分层方法生成更让人们喜爱,与提示更相关的故事。 本文代码及数据整合在fairseq中,非常利于复现。

数据集
WritingPrompts
序列到序列数据集,源是写作提示,目标是一段30词以上的作文。
 从reddit的WritingPrompts板块爬取,有一定的错拼和奇异符号。
经过nltk的符号化,提供的是与处理后的数据集
从reddit的WritingPrompts板块爬取,有一定的错拼和奇异符号。
经过nltk的符号化,提供的是与处理后的数据集
算法与模型
首先用语言模型生成故事的前提和提示,然后据此用序列到序列模型生成故事,从而让故事和条件一致。
模型是基于卷积序列到序列模型,然后加入自注意力机制,考虑到这是2018年transformer刚出现,可以视作不太标准的transformer。
为了更好的生成很长的文本,这里将transformer的自注意力机制中的线性QKV用GRU代替。
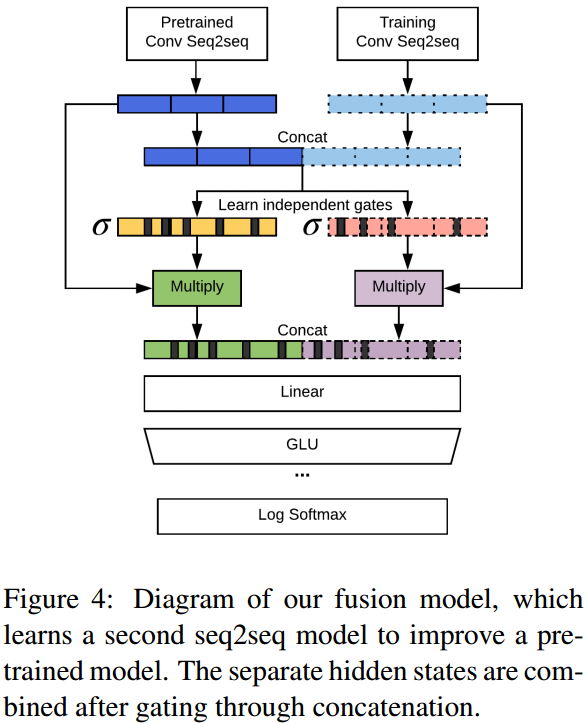 训练的时候参考率一种发表在arxiv上的冷融合的机制,即先预训练语言模型,然后在正式训练是将固定了语言模型拼接指导训练。
训练的时候参考率一种发表在arxiv上的冷融合的机制,即先预训练语言模型,然后在正式训练是将固定了语言模型拼接指导训练。
实验与对比
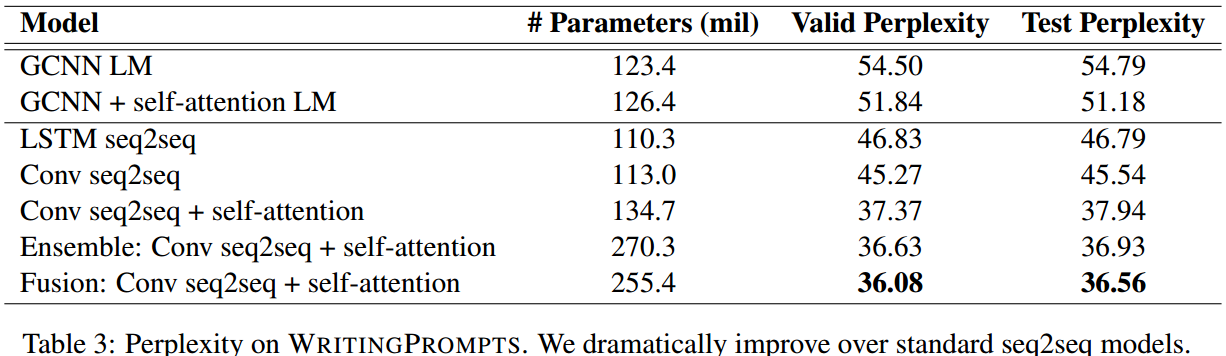
首先是困惑度量化评估,验证模型各个部分的效果。
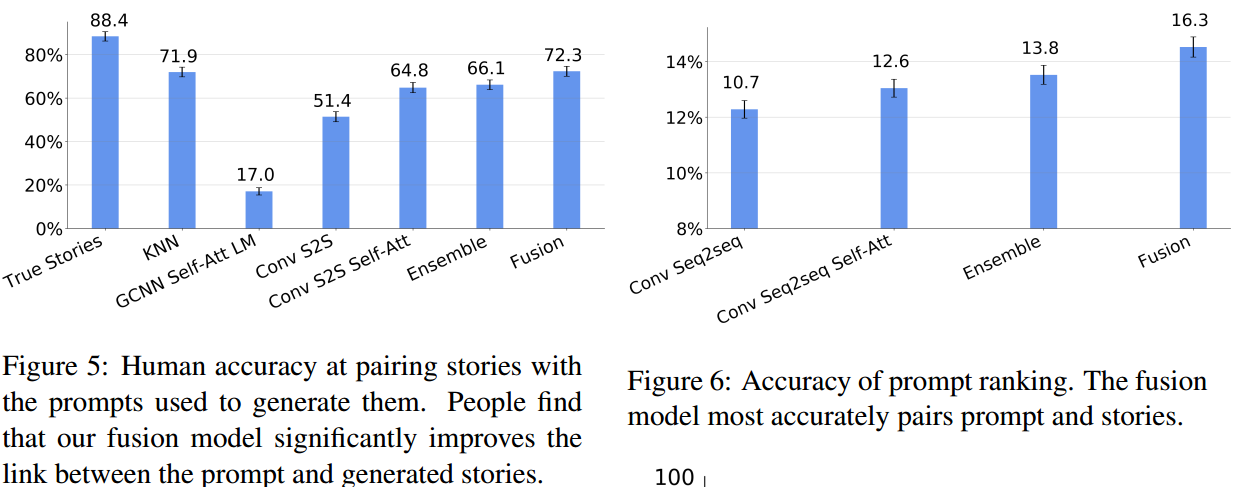
按提示写故事这样的开放问题,使得评估基本只能靠人进行。
作者采用众包方法,来评估故事是否符合主题,即给出真实提示和其他随机9个提示,让人来进行相关性排序。
当然还有对超长文本的效果以及冷融合的效果的分析,以及一些示例。
思考
这应该算是一篇数据集+基线的论文。 既然有了图网络的基线对比,那么在分层的时候引入图网络的机制也许更好。
Author lvcudar
LastMod 2019-12-11