Read Paper 《Human-Like Decision Making: Document-level Aspect Sentiment Classification via Hierarchical Reinforcement Learning》
Contents
URL: https://www.aclweb.org/anthology/D19-1560
简介
EMNLP2019 提出的一种使用分层强化学习可解释性较好的文档级别多方面情感分类方法,据说达到了最优的效果。

算法
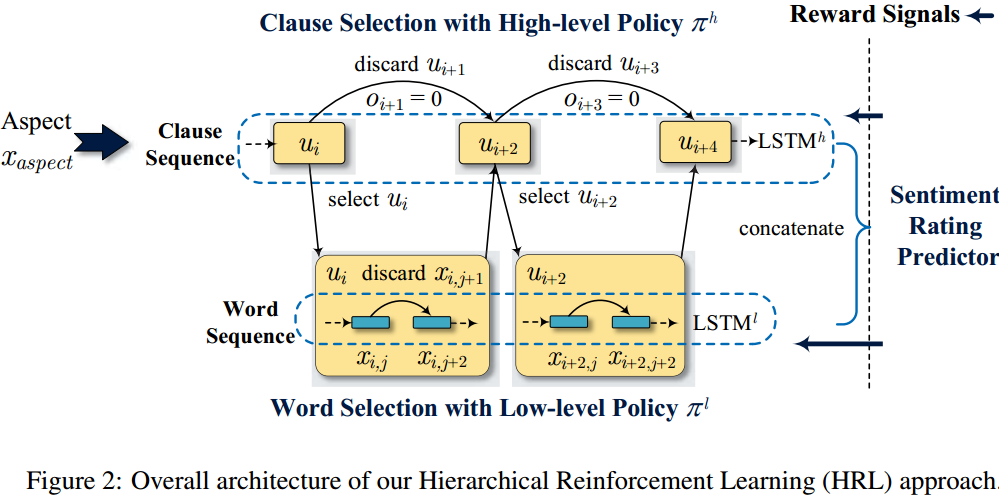
算法整体是用强化学习的方法像人一样,先选择关键句,再选择关键词,最后用选择的信息来作出文本类别判断。
模型使用LSTM来完成词和句的编码以及选择操作,选择是用sigmod对每个词或句的编码二分类实现的,当然还有惩罚要求选择的尽可能少。
训练过程首先预训练词级别的LSTM,类似于情感分类条件下的语言模型,然后再同样预训练句子级别的LSTM,因为句子级别LSTM的输入来自底层词级别LSTM。 预训练好了条件语言模型,再对动作(Action)的参数进行强化学习。这里奖励共有5个超参数来权衡各个方面。
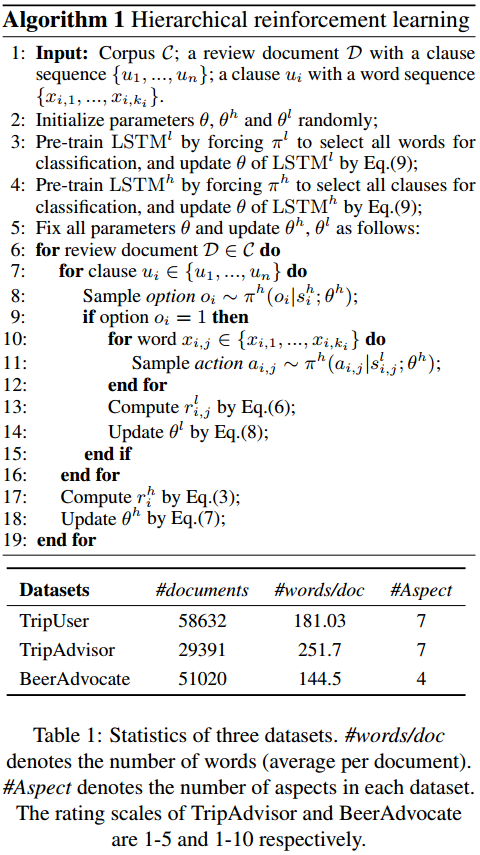
数据集
| Name | Link | Desc |
|---|---|---|
| TripUser | https://www.aclweb.org/anthology/C18-1079/ | 和下个来自同一网站,但作者没给链接 |
| TripAdvisor | http://times.cs.uiuc.edu/~wang296/Data/ | 对旅店在价格、位置、服务等方面的评论 |
| BeerAdvocate | https://data.world/socialmediadata/beeradvocate | 对商品的多方面评价 |
实验与对比
本文在文档级别多方面分类取得了SOTA。
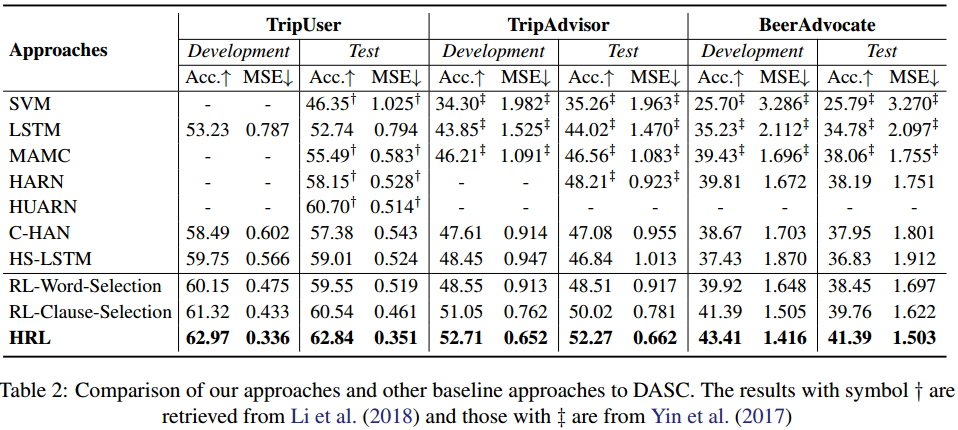
当然还有消融实验来说明预训练和各种策略的有效性。 以及对错误的分析。
最后按照原理给出了可视化效果。

思考
这种分层抽取的文本分类方法应该算是内含了一个条件摘要模型。 感觉如果数据量足够,这套算法也许可以端到端训练而不使用强化学习方法。 这些超参数也许可以再套一层强化学习做架构搜索。
Author lvcudar
LastMod 2019-12-12