Read Paper 《Learning Semantic Sentence Embeddings using Sequential Pair-wise Discriminator》
Contents
URL: https://www.aclweb.org/anthology/C18-1230
简介
COLING2018 通过复述任务学习句子编码,网络单元使用的LSTM,其复述生成实验到2019年底仍然是SOTA。
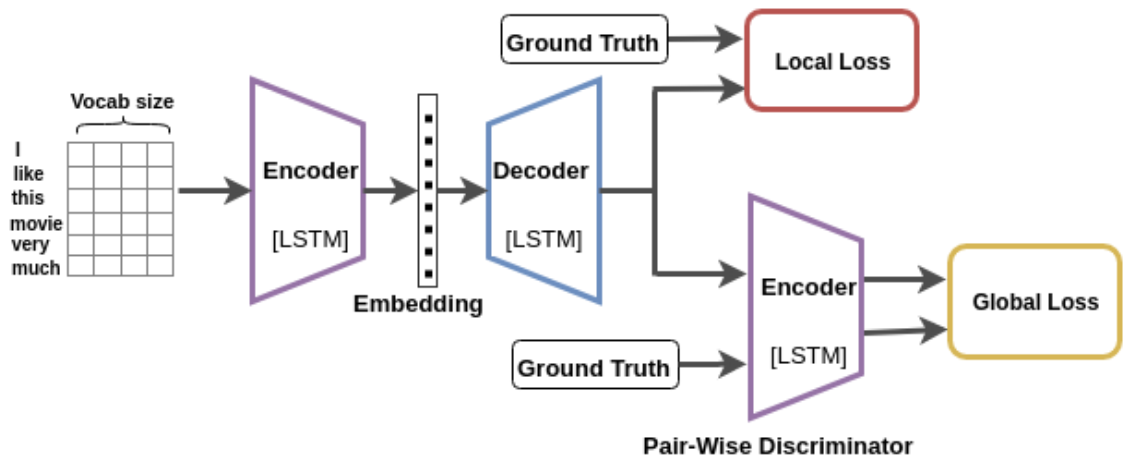
模型
模型由LSTM构成的编码器、解码器、鉴别器三部分组成。 编码器使用时间上的卷积层(Temporal CNN)将独热向量转化成词向量,这一层似乎就是普通的Embeding层。 用序列最后全部输入完成时的那个隐状态作为句子的编码。 解码器接受编码器给出的最终句子编码,尝试用LSTM预测复述句子,并和真实的复述比较得到局部误差损失,这是个类似机器翻译的损失。 鉴别器则是将解码器的输出结果和目标复述一起通过共享参数的LSTM,将最后的状态作为句子编码,得到全局损失。
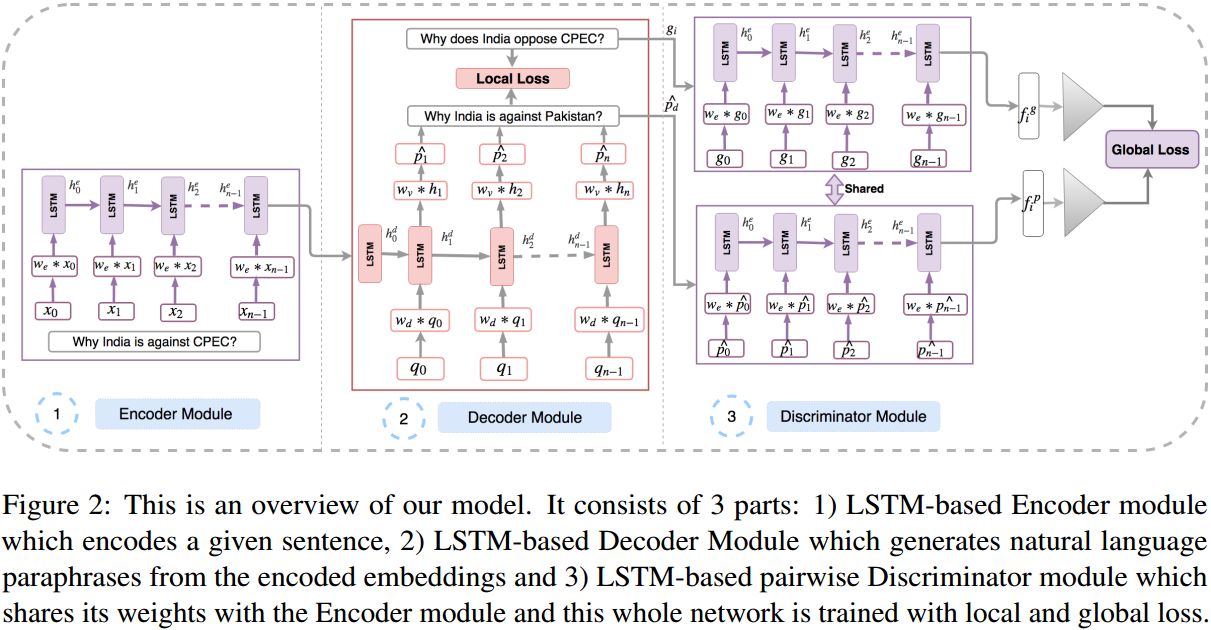
在榜上被简称为EDD-LG(Encoder Decoder Discriminator Local-Global),EDD就是模型三部分,LG代表损失函数的两部分。 L是解码器预测和目标复述间的损失: \( L_{local} = \frac{1}{T} \sum_{t=1}^T q_t \log P(\hat{q_t} | q_0,...q_{t-1}) \) G是预测和目标句通过同一个LSTM-RNN最终编码的差别,之所以叫作全局损失,是因为它不仅要求和真实复述接近,还要求和其他复述内积小: \( L_{global} = \sum_{i=1}^N \sum_{j=1}^N \max(0, f_i^p * f_j^g - f_i^p * f_i^g + 1) \) 其中,p是预测,g是真实,f是鉴别器LSTM最终输出,i是当前,j是其他。
数据集
| Name | Task | Link | Desc |
|---|---|---|---|
| Quora | 复述生成 | https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs | Quora重复问题数据集,超过40万 |
| SST | 语义分析 | https://nlp.stanford.edu/sentiment/ | 斯坦福情感分析数据集,正负面共五类约20万句 |
实验与对比
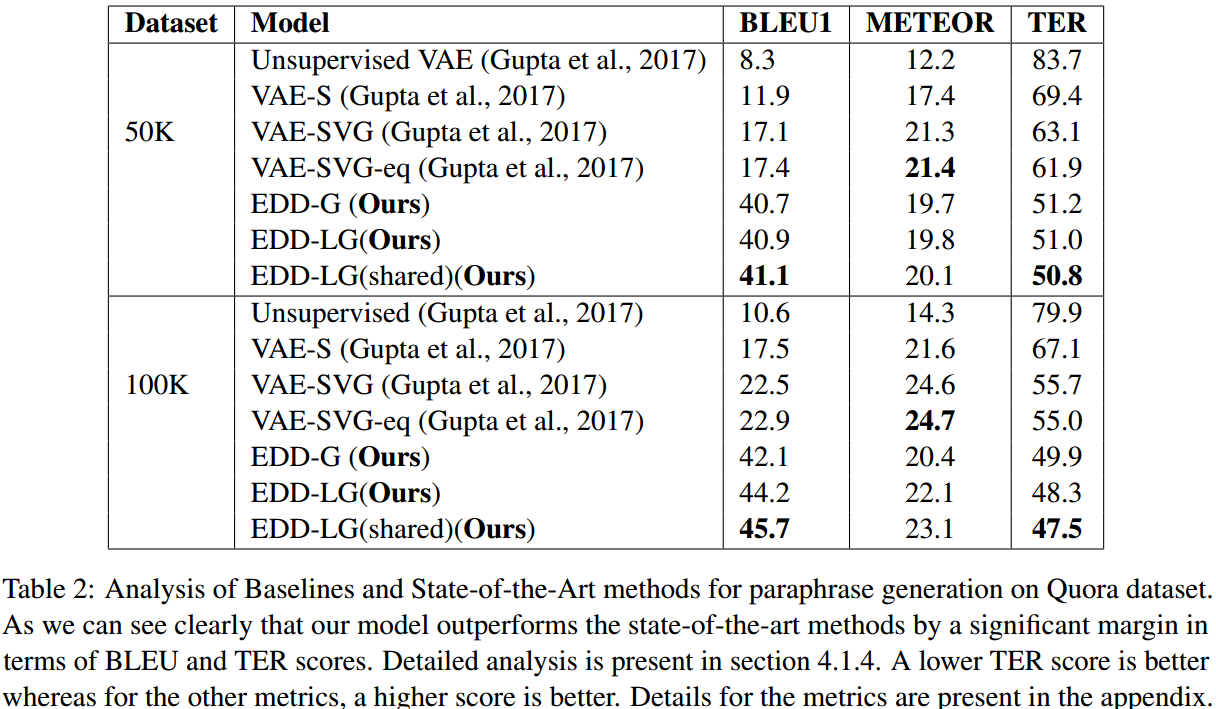
复述生成方面在Quora数据集上用BLEU1、METEOR、TER三种指标进行了比较。
达到了SOTA,但也不是很明显。
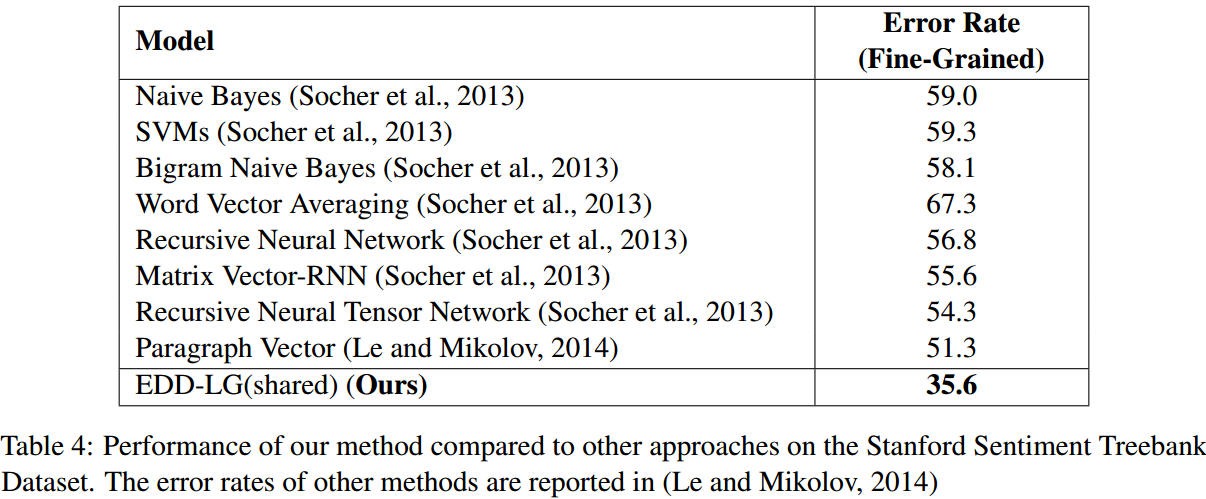
语义分析用的经典的斯坦福数据集。
从错误率上看提升非常明显。
思考
简单美观效果很好,也开源了代码,竟然是用lua写的。 鉴别器的损失函数有点类似后来的三元损失,本文的方法可能比较慢或者作了优化。 复述生成没有和使用BLEU4和ROUGE-L这两个常用指标。
Author lvcudar
LastMod 2019-12-27