Read Paper 《Measure Country-Level Socio-Economic Indicators with Streaming News: An Empirical Study》
Contents
URL: https://www.aclweb.org/anthology/D19-1121/ https://github.com/BBN-E/ecim
简介
EMNLP2019 对于国家经济指标(如失业率)统计困难,提出了一种基于新闻事件的估计方法,和经济指标有很强的相关性。
数据集
Gigaword包含了1994-2010的570万文章。
方法
从数据集的大规模新闻中提取事件及其事件和位置,然后对每个社会经济指标在每个时间点汇总相关事件,从而产生相应指标对预测序列。
具体的,抽取时间采用语义角色标注(SRL),而时间和地点来自文档数据或相同句子。 对于每个指标累加一段时间内相关事件出现次数$\sum_{e \in Ei} N{e, t'}$, 考虑新闻增长,对月度进行归一化除以所在月份文章总量Mt',最终在一段时间进行平滑。
\[ ECIM_{i,t} = \frac{1}{T} \sum\limits_{t' \in [t - \frac{T}{2}, t + \frac{T}{2}]} \frac{\sum_{e \in E_i} N_{e, t'}}{M_{t'}} \]
实验
对失业率(UR)芝加哥期权交易所波动率指数(VIX)和经济政策不确定性(EPU)三项重要且公开对指标进行估计。
如图似乎估计还有一定提前预测能力。
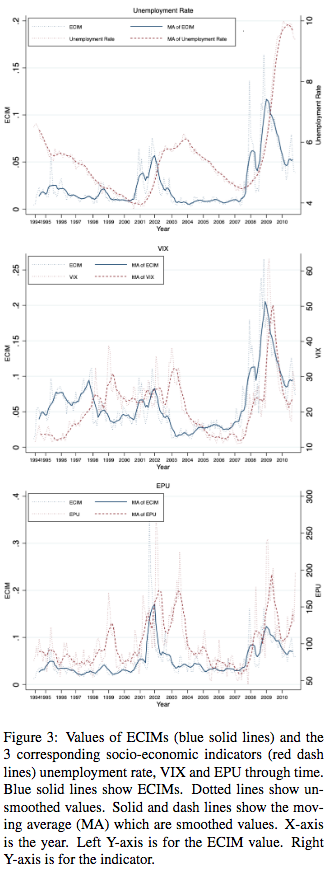
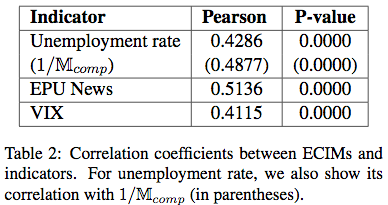
还有皮尔逊系数和p值对量化分析(p值全0)
思考
想法很新,方法很简单,实用性和效果感觉一般。
Author lvcudar
LastMod 2019-12-07