Read Paper 《Paraphrase Diversification Using Counterfactual Debiasing》
Contents
URL: https://aaai.org/ojs/index.php/AAAI/article/view/4665
简介
AAAI2019 通过随机初始化和导向生成与之前不同的复述实现多样化,其中拼凑了多种复述相关数据集。
算法与模型
作者基于AAAI2018的《A deep generative framework for paraphrase generation》在变分自编码器复述模型的多样性方面提出了由三个改进点组成的方案。如图语言模型用的GRU。
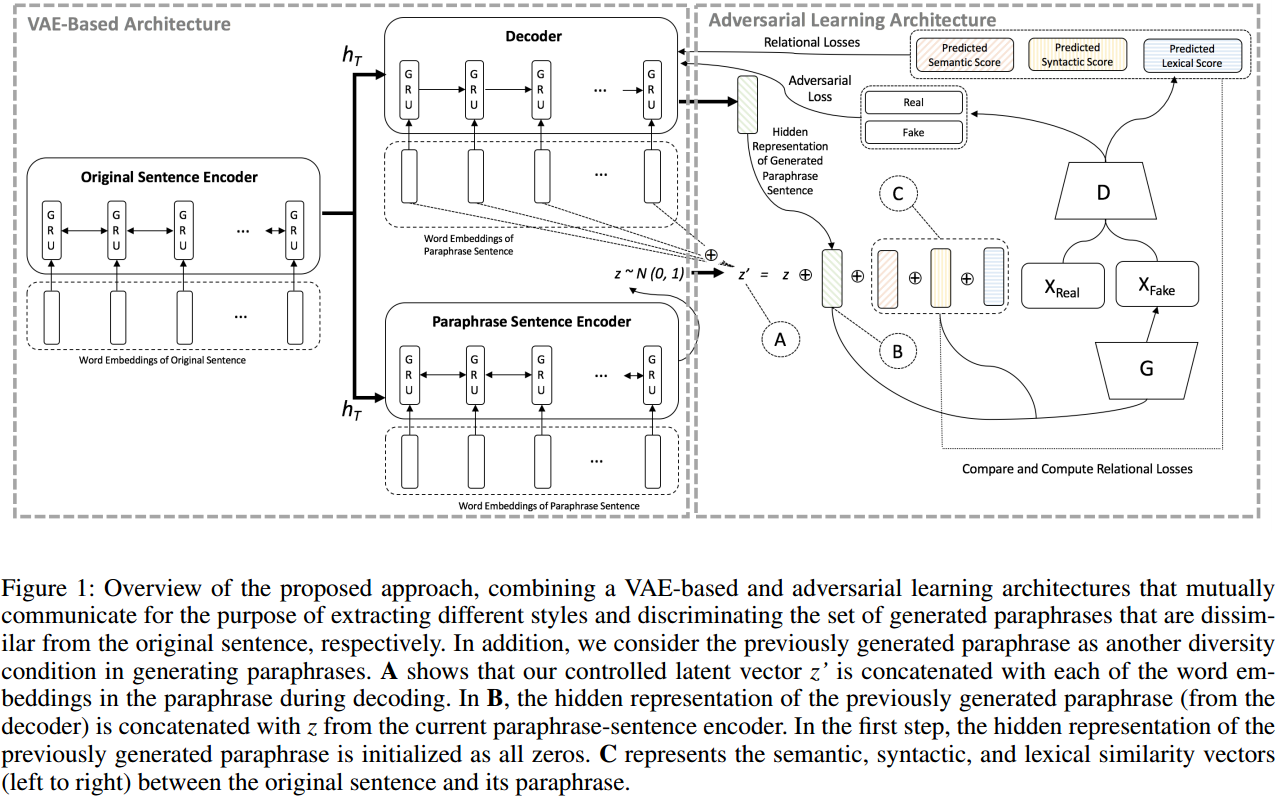
- 不单单使用一个无条件隐变量z, 而是根据导向获得z’。具体方法是将随机采样的z和3维导向向量[语义是否相同, 句法是否相同, 词是否相同]拼接, 然后过一层网络得到z’。
- 设置与之前生成的不同来实现多样性。这里将上一个z’和生成句子的隐状态h拼接再过一层网络得到新的z’,并用后句和前句的词语覆盖损失来训练。
- 要超越训练数据的多样性。目前的复述数据集大都是两句一对,且高度重复。为了充分利用有偏置的数据,采用对抗方法,对导向向量的句法和词法维度进行负采样,通过对抗训练强化导向向量的指导作用。
数据集
| Name | 简介 |
|---|---|
| Quora | Quora网站重复问题数据集 |
| Microsoft | 微软2005年从网络新闻标注的5800对复述句子 |
| SNLI | 斯坦福推理数据集,这里用继承关系那部分的19万对 |
| MSCOCO | 目标检测数据集,每个图片有5句描述 |
| Wikipedia | 13.7万对维基百科句子及其简化,来自ACL2011《Simple english wikipedia: A new text simplification task》 |
作者按照基线的方式将数据集划分训练、验证、测试。 将数据集中非复述的部分用于负采样,没有非复述对的则随机抽取不同对的组成非复述对。
实验与对比
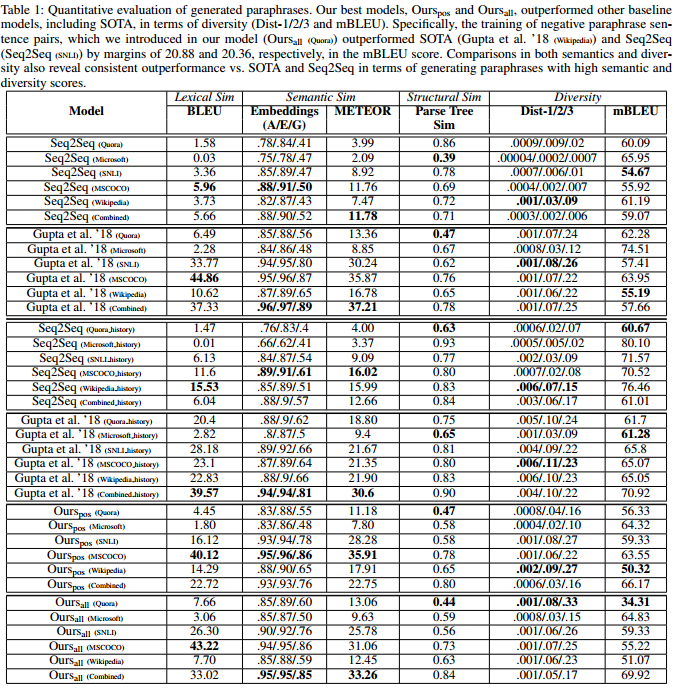
指标采用相似性和多样性两组指标: * 相似性由词法相似性BLEU、语义相似性词向量距离、考虑近义词的相似性METEOR、结构相似性解析树相似度组成。 * 多样性由n元组差异Dist-n、复述间平均相似性mBLEU组成。
同基本Seq2Seq和基线的对比显示在相似性指标差不多的情况下,本文的方法多样性有明显的进步。
思考
虽然文中没有开源链接,但是表示使用NSML平台完成的实验。
Author lvcudar
LastMod 2020-02-02