Read Paper 《Paraphrase Generation with Latent Bag of Words》
Contents
URL: http://papers.nips.cc/paper/9516-paraphrase-generation-with-latent-bag-of-words.pdf https://github.com/FranxYao/dgm_latent_bow
简介
NIPS2019 唯一一篇复述生成论文,扩展序列到序列模型在不牺牲端到端优势的情况下实现良好的解释性。
模型
本文是基于序列到序列模型,改进中间状态和传递过程实现的,编解码器采用LSTM。
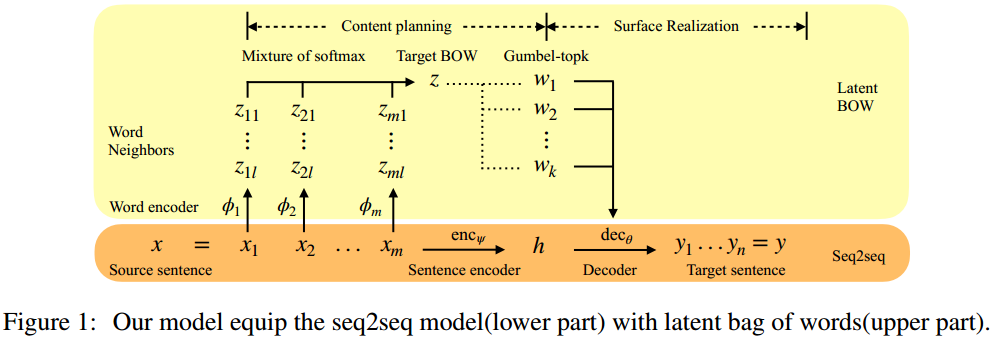
算法
本文将序列到序列的中间变量建模为BOW(Latent Bag of Words)。
首先在编码器顶层LSTM后面用神经网络得到每一步的邻近词独热向量 $z_{ij}$ , \( p(z_{ij} | x_i) = Categorical(\phi_{ij}(x_i)) \) 每步假设都计算l个邻近词,即j=1,2...l, $\phi$ 是神经网络。 然后将输入每一步的邻近词组合起来构成BOW, \( \tilde{z} \sim p_\phi(\tilde{z} | x) = \frac{1}{ml} \sum\limits_{i,j} p(z_{ij} | x_i) \) 接着再以z为条件从中选取前k个用于解码。 最后合并损失函数 \( Loss = L_{S2S} + L_{BOW} = E_{(x^*, y^*) \sim P^*, z \sim p_\phi(\tilde{z}|x)} [-\log p_\theta (y^* | x^*, z)] + E_{z^* \sim P^*} [-\log p_\phi (z^* | x)] \) 其中 $P^$ 为BOW的真实分布,比如多个目标句的所有词, $z$ 是 k-hot 向量。
从z或者说k-hot向量采样不可导,作者使用了ICML2019的Gumbel Top-k Trick来实现微分。
数据集
| Name | Link | Desc |
|---|---|---|
| Quora | https://www.kaggle.com/aymenmouelhi/quora-duplicate-questions | 洋知乎重复问题数据集,每对问题重复或不重复 |
| MSCOCO | http://cocodataset.org | 目标检测数据集,每幅图有5个描述 |
本文没有使用机器翻译类的复述数据,而是用了两个不是那么专门但是质量很高的数据集。
实验与对比
基线选择了2016年的残差序列到序列注意力模型和2017年的贝塔VAE模型。
BOW成功超越了基线,以及自身的消融版本。
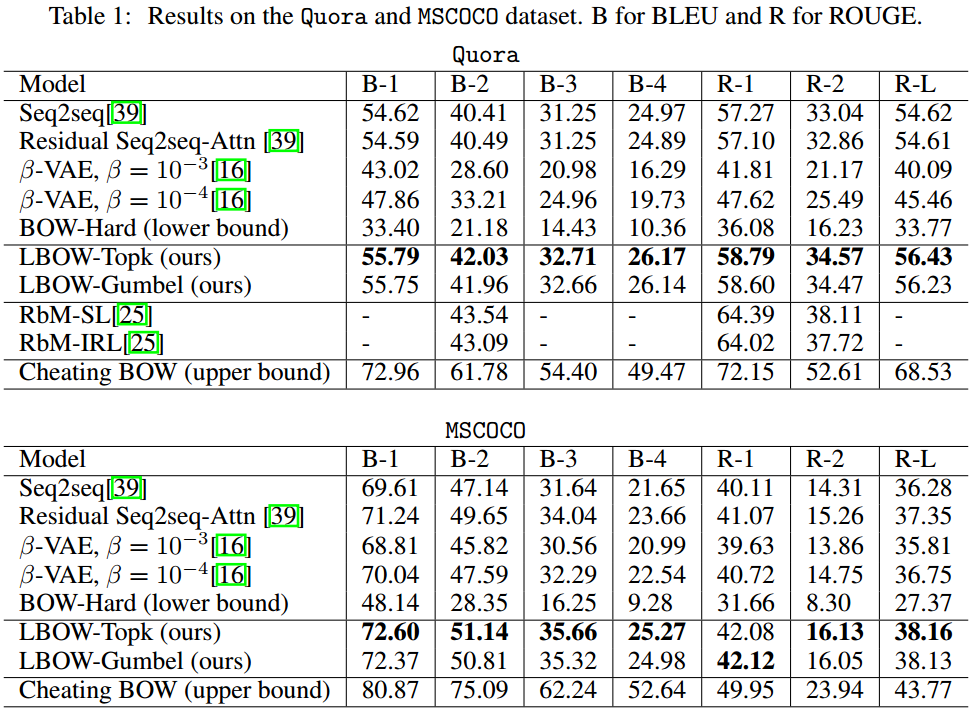
本文方法主要的优势在于可解释性,作者分为无监督学习邻近词和生成过程使用BOW指导。

后面还对可解释性进行了量化分析并对可控性进行了展望。
思考
一对多的复述数据集很有必要。
Author lvcudar
LastMod 2019-12-13