Read Paper 《Recurrent Positional Embedding for Neural Machine Translation》
Contents
URL: https://www.aclweb.org/anthology/D19-1139
简介
EMNLP-IJCNLP2019 用单独的RNN为Transformer学习位置编码,取得更好的效果。
数据集
- WMT14EN-DE: 常用的大型开放机器翻译数据集, fairseq中有预处理脚本。
- NIST_MT_ZH-EN: 美国国家标准化研究院的机器翻译数据集, 在LDC上有提供但尚不知如何下载。
方法
不使用原始Transformer论文中的正弦位置编码。 而是将词向量分层两部分其中一部分用来表示位置信息,因此模型维度是表示位置的维度加上表示意思的维度,其中表示位置的维度是变量,实验中有进行对比。 将表示位置的在编解码器分别通过双向和单向RNN(和Transformer类似)得到循环位置编码(RPE)。
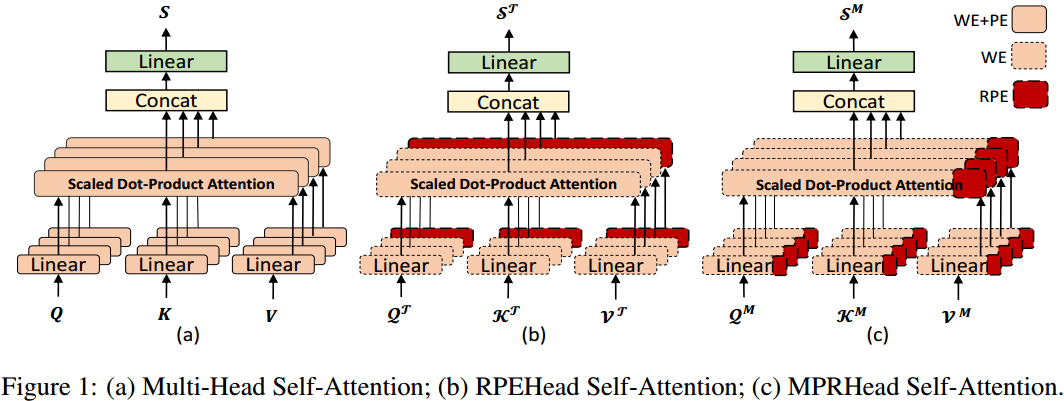
作者设计了两种使用RPE的方法,一种是对RPE单独进行自注意力,然后和其他自注意力头的输出拼接传入下一层; 另一种是将RPE直接和表示意思的部分拼接送入Transformer中。
实验与对比
作者主要通过和基线的对比说明RPE的作用,而同其他模型的对比并没有明显优势。同时也测量表明RPE不会显著的增大模型。
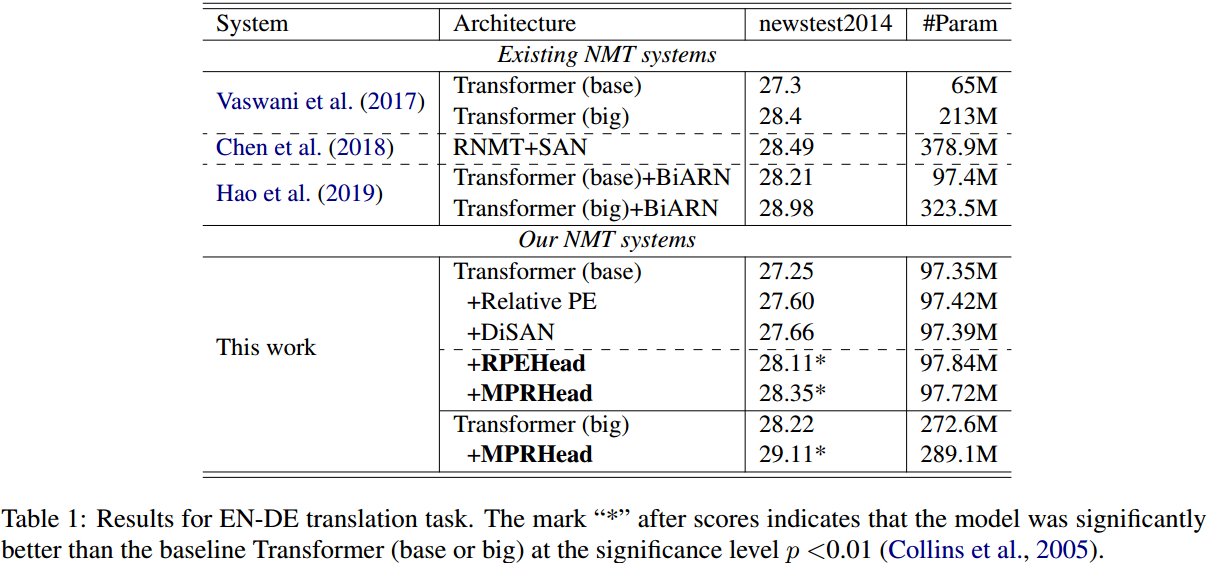
消融实验说明只要采用RPE就会有提升,不论维度。
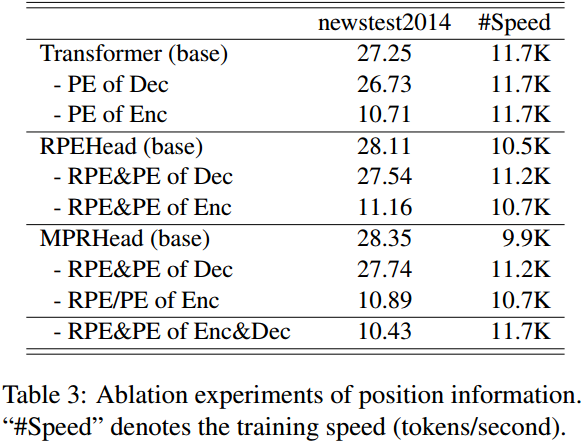
但是对于去掉位置编码的消融实验值得关注,在编码器部分去掉正弦位置编码或循环位置编码影响要远大于解码器端。
思考
这个新设计的RPE感觉和位置相关性不大,也许可以算是一种集成策略。
Author lvcudar
LastMod 2019-12-21