Read Paper 《Sequence Generation: From Both Sides to the Middle》
Contents
URL: https://www.ijcai.org/proceedings/2019/760
简介
IJCAI2019 一种从两边到中间的序列生成方法,并证明对机器翻译和文本摘要能有速度和精度的同时提升。
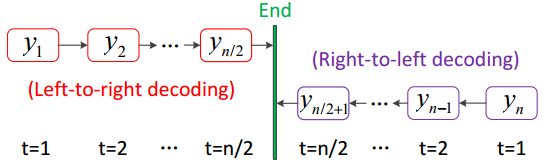
算法与模型
从两边到中间的句子生成方法是再Transformer的基础上对解码部分进行了修改。
编码器使用普通Transformer的编码器。
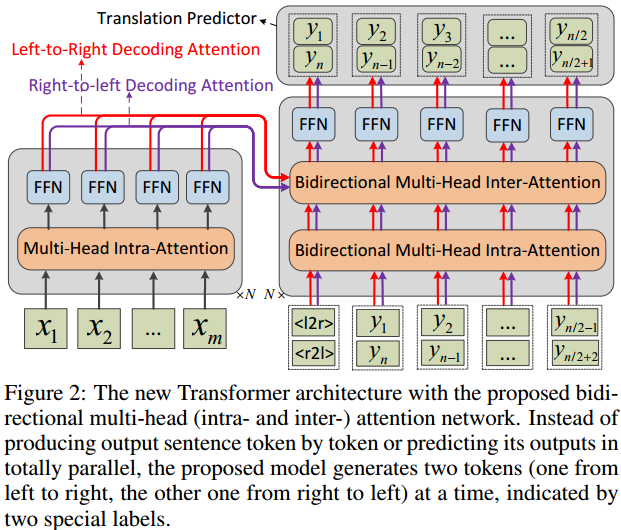
解码器因为同时从两端开始解码,对注意力部分将前向和反向的注意力进行了整合。
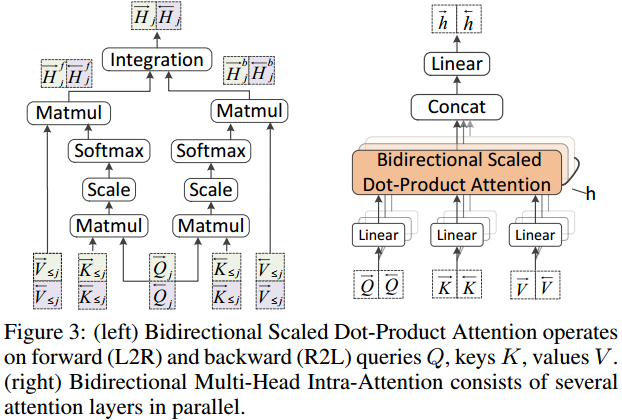
\( \overrightarrow{H}_j = Integration(\overrightarrow{H}_j^f, \overrightarrow{H}_j^b) = \overrightarrow{H}_j^f + \lambda * \overrightarrow{H}_j^b \)
并不是直接的拼接或相加而是考虑了权重。并以此替换了原来的自注意力运算。
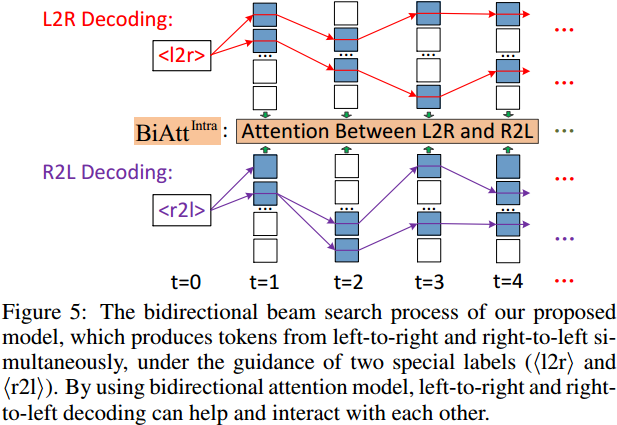
训练上作者表示采用了蒸馏方法。
对于测试时的束搜索,这里则在排序的时候同时考虑两端的混合注意力结果。
数据集
机器翻译选取了WMT14En=>De, NIST_Ch=>En, WMT16En=>Ro。 其中中英翻译训练来自LDC2000T50, LDC2002T01, LDC2002E18, LDC2003E07, LDC2003E14, LDC2003T17和LDC2004T07, 验证使用NIST2006,测试使用NIST2003-2005。 另外两个数据集论文中也有详细的使用说明。
文本摘要用English Gigaword Dataset训练,用DUC2004测试。
实验与对比
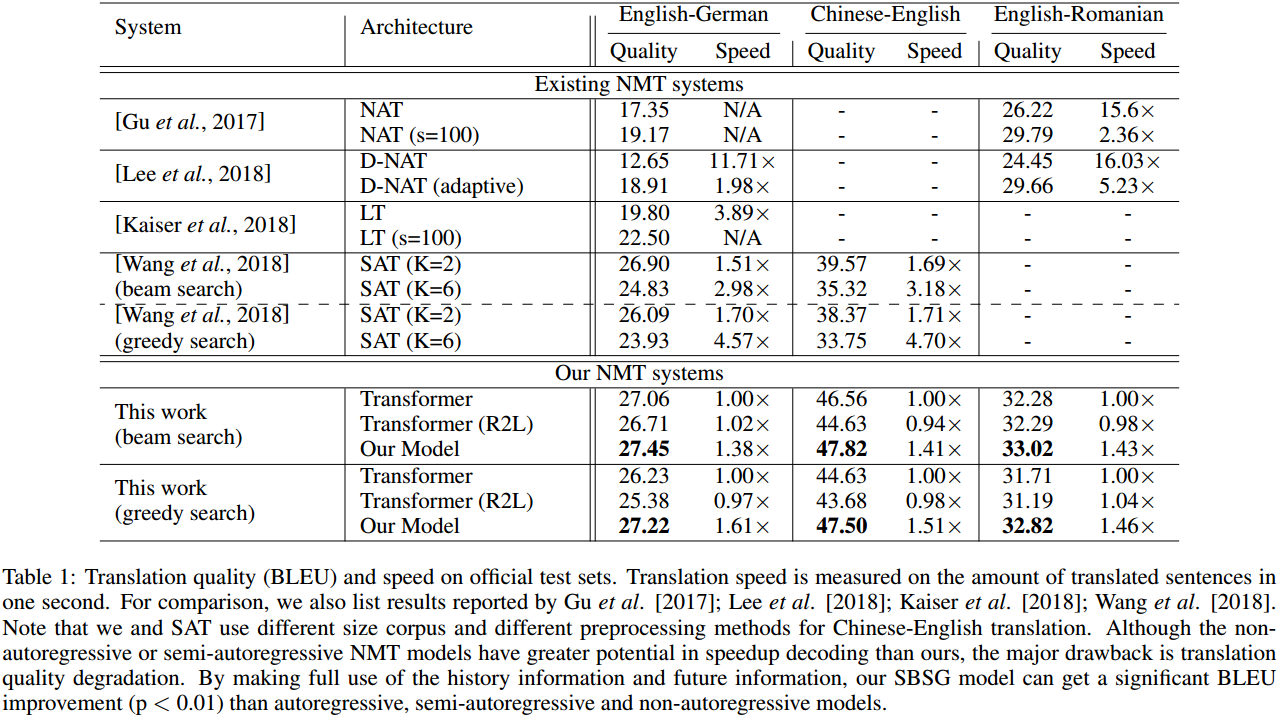
机器翻译上不仅对标准Transformer有速度和质量的双重提升。还和其他加速的改进方案进行了比较,都取得了精度上的超越。
论文中没有专门的消融实验,而是用举例和划分长度评测的方式验证了本方案能解决输出长度不平衡的问题。
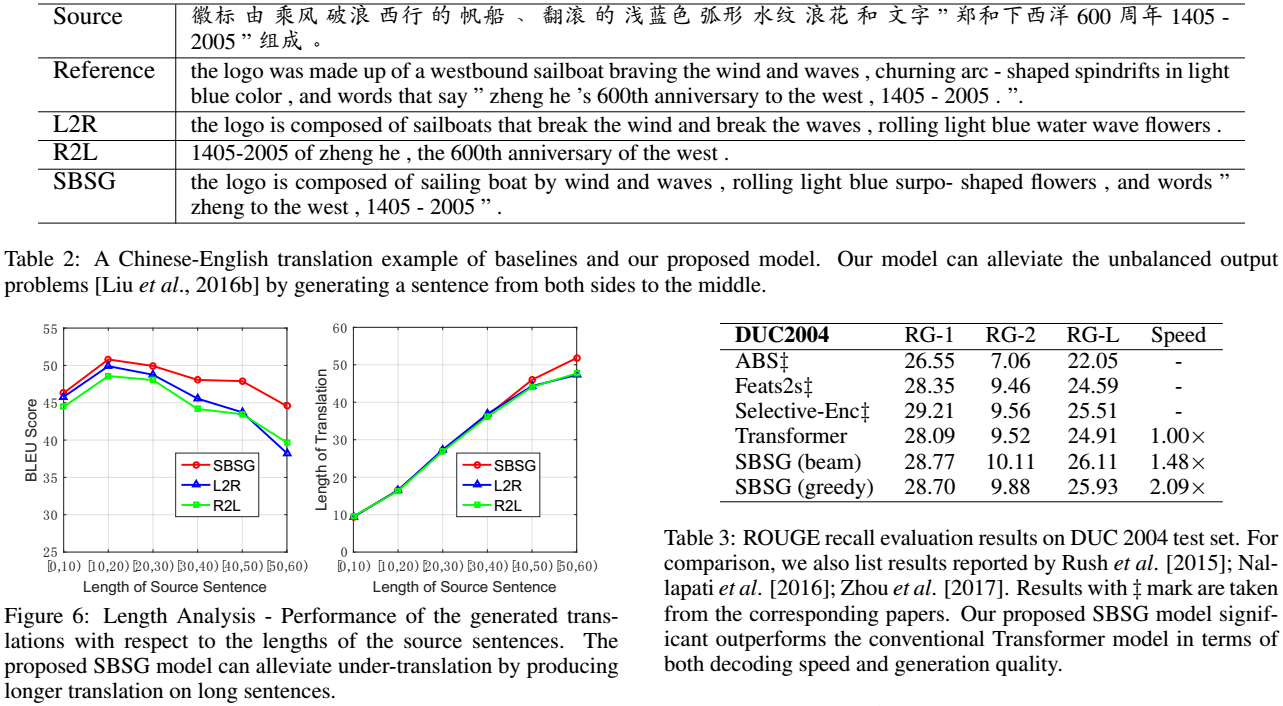
在文本摘要方面对Transformer的改进也获得了质量和速度的双重提升。
思考
很不错的想法和实验,可惜没有开源代码。 应该还可以在根据中心词向两侧生成句子时用类似的方法引入两侧间的关联。
Author lvcudar
LastMod 2020-02-18