Paper Read 《Simple and Effective Paraphrastic Similarity from Parallel Translations》
Contents
URL: https://www.aclweb.org/anthology/P19-1453/ https://github.com/jwieting/simple-and-effective-paraphrastic-similarity
简介
ACL 2019 利用平行语料学习句子相似性,但是不利用回翻技术,而是直接在平行预料上用三元损失函数。
数据集
2012-2016 SemEval Semantic Textual Similarity (STS) shared tasks
算法
在平行语料中每次选一个句子s,它对应的翻译t和其他的翻译t'。 以让s和t的句子编码尽可能相近,s和t'的句子编码尽可能远为目标来优化。 \( \min\limits_{\theta_{src}, \theta_{tgt}} \sum\limits_i [\delta - f_\theta(s_i, t_i) + f_\theta(s_i, t'_i)] \) 其中 $f_\theta(s, t) = \cos(g(s; \theta_{src}), g(t; \theta_{tgt})), \text{g is encoder.}$
这样就省去了回翻的算力消耗。 如果是多语言翻译语料,则t'会在所有的集合中随机抽取,而不是向双语言语料那样只在对应的翻译语言上。
模型
编码器主要采用子词编码取平均的方法(SP)。 也对词编码、三元语言模型、双向LSTM等进行了实验。
实验与对比
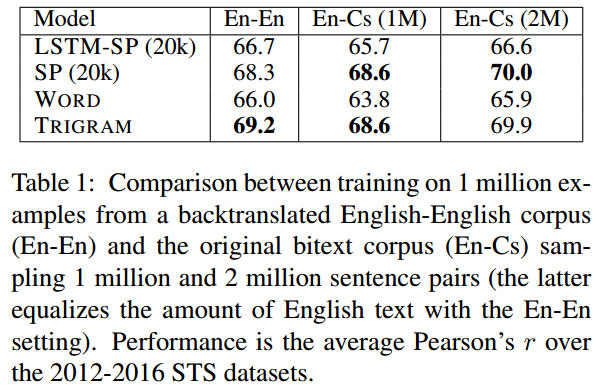
双语实验,相似性都是英文句子间相似性。
说明了本文的子词编码取平均的方法(SP)优于其他句子编码方法。
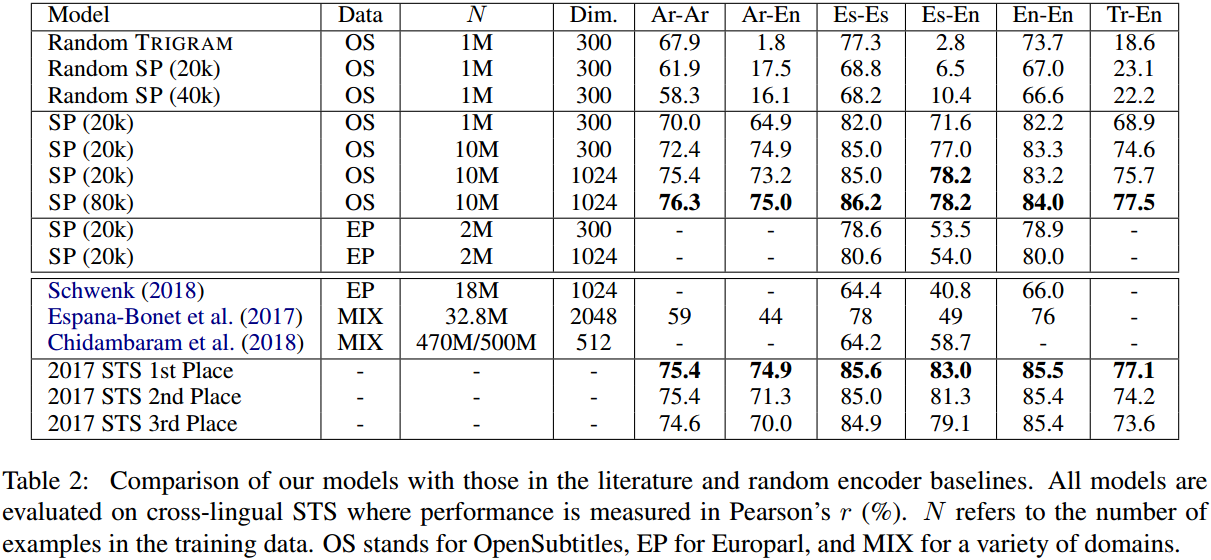
多语言实验,训练语料是多语言平行语料,指标是跨语言相似性准确程度。
说明了本文的不依赖回翻的方法在跨语言相似性上的优越性。
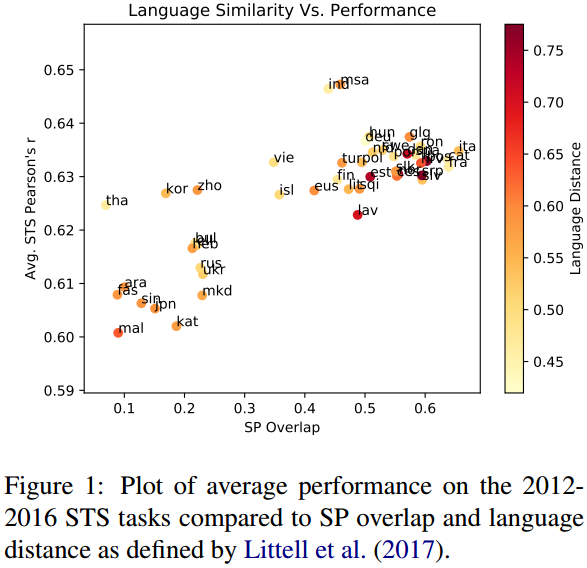
作者还通过消融实验说明结果和语言的选择是无关的。
思考
本文说明了相似性度量可以省去回翻这一步,节省大量时间与算力。 至于可省去回翻是否因为字词编码效果好,消融说明感觉不是很充分。
Author lvcudar
LastMod 2019-10-10