Survey of Machine Translation Dataset
Contents
对机器翻译数据集的调研
简介
| Abbr | Name | Link | Scale | Desc |
|---|---|---|---|---|
| WMT | Workshop on Statistical Machine Translation | https://www.statmt.org | GB | 统计机器翻译研讨会,每年举行机器翻译评测,数据集规模大、多样且开放 |
| IWSLT | International Workshop on Spoken Language Translation | http://iwslt.org | MB | 口语翻译国际研讨会,在TED演讲数据集上评测,每年递增数据且开放 |
| MT | Open Machine Translation Evaluation | https://www.nist.gov/itl/iad/mig/open-machine-translation-evaluation | KB | 美国标准技术研究所的机器翻译评测,数据需要通过语言数据联盟注册获取,小规模新闻翻译 |
WMT
统计机器翻译研讨会,后来改名为机器翻译会议(Conference on Machine Translation)
最早从新闻翻译开始,后来逐渐加入生物医药语料翻译,鲁棒翻译——针对网络环境不规范文本,相似翻译——针对稀缺语料语言的翻译。 会议提供数据、处理工具和评测工具,每年举行。从2017年加入中文。 在第二年会公开上一年官方预处理的数据,即官方推荐的符号化(分词)版本。 数据来源首先时联合国文件的多语言版本,以及大量网络爬取文章和新闻的人工标注。
官网首页好像没有改名后的连接,大致规则是加上“wmt年份后两位”,如 https://www.statmt.org/wmt19 官网直接提供各种原始语料和官方预处理版本。 数据规模非常庞大,比如2017年的中英新闻翻译就有两千万平行语料,是最具影响力的机器翻译平台。
WMT14及以后的数据集都常见与论文中。
IWSLT
口语翻译国际研讨会
数据集时来自TED演讲的各国语言字幕,早年提供双语平行语料,17年开始有多语言翻译语料。 数据集以英语为核心,毕竟是美国的东西。 奇怪的是,中英-英中这样的数据集不完全一样。
数据集不在研讨会的官网呈现,而是由WIT——欧盟的转录与翻译对话的网页清单来提供。每年会加入新数据。 其中,2014年和2017年的数据最为常见,fairseq也集成了预处理脚本。
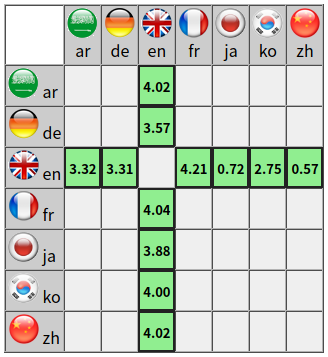
上图时17年下载页面,左侧是源,上方是目标,数字表示目标句子总尺寸。
NIST-MT
美国标准技术研究所公开机器翻译评测
这个机器翻译有点像冷战产物。从2000年开始就有中文和俄语。 数据质量很高,中文是新华社新闻及其翻译,但是数量比较少,只有几万句。 这个数据集2005年附近的版本常被采用,简写为MT05等。
这个数据集是半公开的,官网不提供数据,通过语言数据联盟后来采用同样数据的任务挑战来下载数据。 而语言数据联盟需要注册,甚至缴费才能获取数据。
Others
因为机器翻译任务数据多且成熟,论文中几乎没有见不到其他数据集。 当然,有人热心标注了新的机器翻译数据集通常也会整合到WMT的数据集中。 最近发现中文科技在线的中英文摘要似乎是不错的数据集,平均每月大约100篇论文。
Author lvcudar
LastMod 2019-12-26