Read Paper 《Text Level Graph Neural Network for Text Classification》
Contents
URL: https://www.aclweb.org/anthology/D19-1345
简介
EMNLP2019 为文本分类构建低资源消耗的图网络,设计了一种为每个文本单独构建图的方法。
数据集
- R8&R52: https://www.cs.umb.edu/~smimarog/textmining/datasets/
- Ohsumed: http://disi.unitn.it/moschitti/corpora.htm
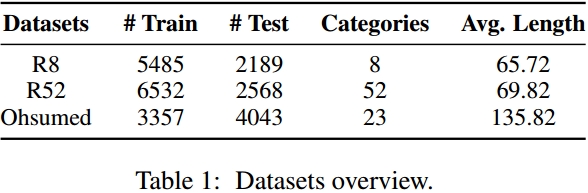
算法与模型
对于之前为文本库建立统一的图,规模太大而且不易加入新的文本的情况,这里为每个文本单独构图。 首先将某个文本中所有出现的单词随即初始化为词向量,然后从每个单词向前后的p个单词连边。 有点类似word2vec的样子,同时这些词向量也是可以训练的。 这样图的节点书就是当前文本的不同单词数,节点属性就是就是词向量,每个图的规模大大缩小。 词向量应该是共享的。
为了得到分类结果,这里使用了消息传播机制,好像就是图卷积。 \( M_n = \max\limits_{a \in N^p_n} e_{an} r_a \) \( r'_n = (1 - \eta_n) M_n + \eta_n r_n \) r是节点属性e是便就是用相邻节点的属性更新当前节点。
最后用softmax得到分类预测 \( y_i = softmax(Relu(W \sum\limits_{n \in N_i} r'_n + b)) \) 不过感觉W矩阵导致节点排列顺序和结果有关。
实验与对比
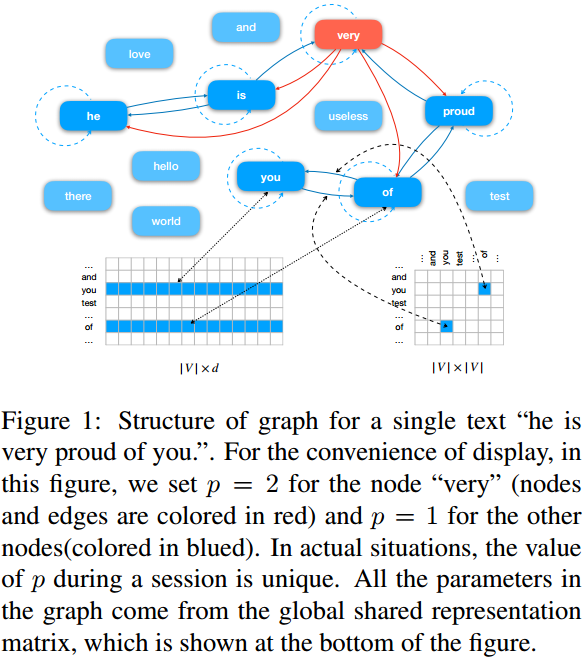
和基线的对比显示本文的方法能够超过所有的基线。
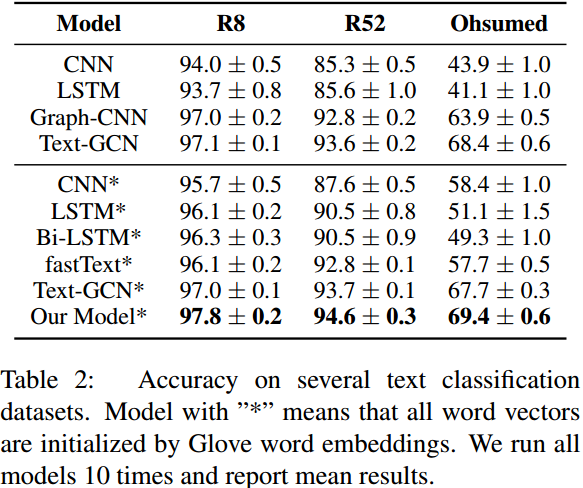
和图网络类的模型相比,本文的内存消耗几乎只有其十分之一。
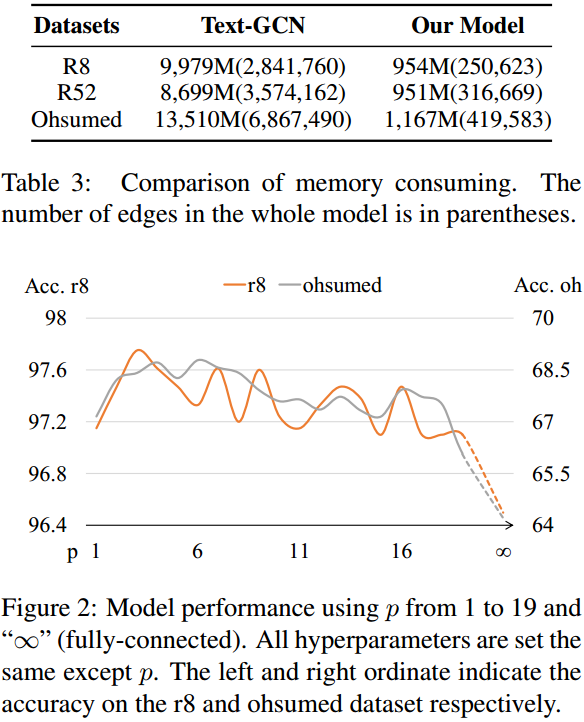
当然还对连边的跨度p进行了枚举,以及各个模块的消融实验。
思考
消息传播机制MPM最后softmax的时候是受到节点顺序影响的。 虽然按照出现顺序排列可能是很好的方式,但没有消融实验说明这一点感觉略有不足,不过毕竟是短论文。
Author lvcudar
LastMod 2019-12-11