Read Paper 《Toward Controlled Generation of Text》
Contents
URL: http://proceedings.mlr.press/v70/hu17e.html
Code: Official-Texar PyTorch
简介
ICML2017 尝试生成通顺的符合设定属性(情感、时态等)的短句。
数据集
| 名称 | 简介 | 链接 |
|---|---|---|
| IMDB | 大型电影评论数据集 | https://www.imdb.com/interfaces/ |
| SST | 标注情感和语法的电影评论 | https://nlp.stanford.edu/sentiment/index.html |
| Lexicon | 句子的语义及其关键词标注 | 参考文献 https://dl.acm.org/citation.cfm?id=1220619 |
| TimeBank | 标注文档中句子时态的数据集 | http://timeml.org/timebank/timebank.html |
模型
模型看起来有些类似GAN,原始样本经过编码器得到编码z,在条件c的参考下,生成器生成符合条件的样本。
为了解耦或者说条件的可解释性,c的每个维度控制不同的条件,比如第一维的01表示情感积极消极。
训练时c为真实的标签,并用重构损失训练编码器和生成器生成真实的句子。
而鉴别器则负责让生成的结果符合c中设置的属性。
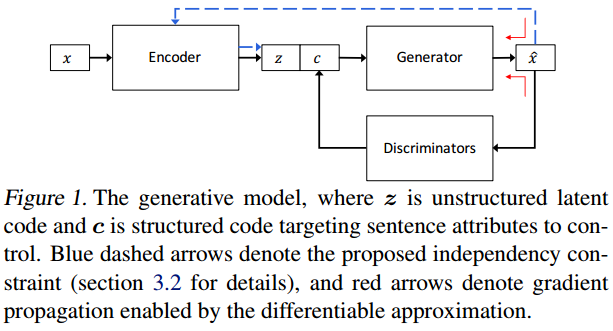
算法
为了成功求解,作者采用了唤醒-睡眠方法来达到优化目标。
这不像传统的VAE同时优化生成和鉴别过程,而是像GAN一样轮流优化。

实验与对比
作者和NIPS2014的Semi-supervised learning with deep generative models
对比了生成和鉴别的精度,这篇baseline本来是做MNIST条件生成的。
还提供了同时生成各种属性的效果。
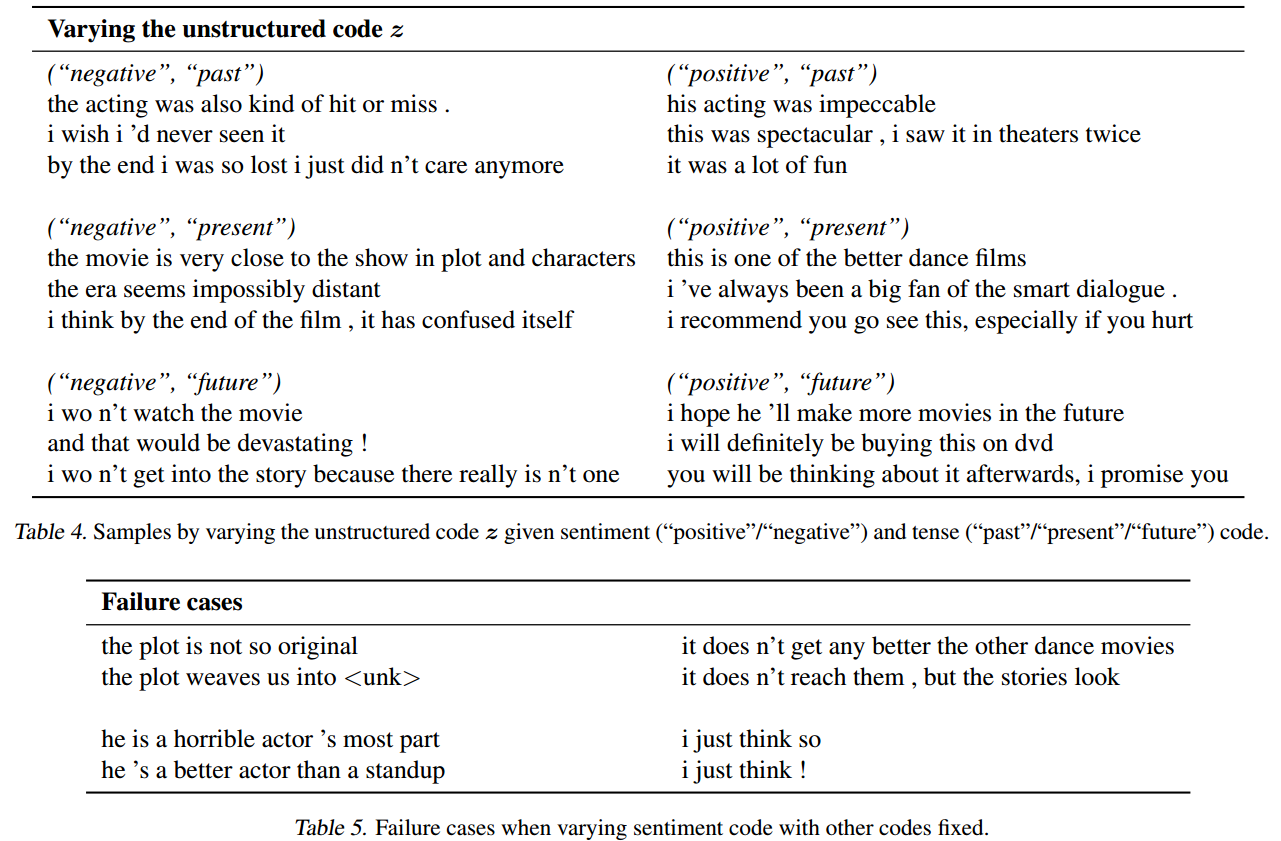
思考
感觉唤醒-睡眠方法和GAN的对抗训练很像,反而没使用VAE损失函数能同时包含生成和鉴别的优点。 似乎像是GAN,而不是改进的VAE。
Author lvcudar
LastMod 2019-11-06