Read Paper 《Unlimited Road-scene Synthetic Annotation(URSA) Dataset》
Contents
URL: https://ieeexplore.ieee.org/document/8569519
TL;DR
ITSC2018 解决内部资源不可访问的问题,借助商业游戏GTAV构建大型语义分割数据集(4T+).
Dataset
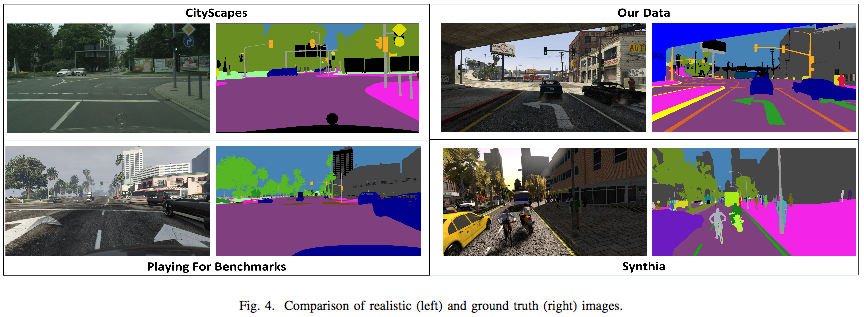
来自GTA5主要道路的行车视角语义分割数据集,道路上车道线和标志有不同类别。
https://uwaterloo.ca/waterloo-intelligent-systems-engineering-lab/ursa
Approach
本文提出了FMSS的概念——磁盘上的纹理文件、模组名称、着色器索引、采样显示数据,它们共同构筑了每个像素的语义标识。
然后就是超像素的概念,即由一些连续的由同样几个FMSS组成的像素区域。

通过CodeWalker得到总共1178355种FMSS,其中56540和道路场景有关。 文中说通过 in-game AI drivers(这里不清楚具体如何操作) 可以得到道路图,然后让车按照一定方式行进得到相关FMSS的场景截图用于标注。 之后将所有截图通过亚马逊众包标注每一个超像素属于哪个类别(实现、虚线、标志等),标注后每种超像素将和一组FMSS关联(有冲突要投票)。 有了实景语义和FMSS的关系,让AI自动在道路上行进,通过DeepGTAV可以得到最高画质但图像,并用FMSS推断出每个像素但语义。
Performance
标注耗时上是有限的点击标注。 实验说明通过这种仿真数据的训练的模型可以在真实数据上获得提升。
Thoughts
一种蛮hack但方法,如果RStar能自己为AI研究贡献一些工具或数据集就好了。
Author lvcudar
LastMod 2019-11-25